
- We aim to revolutionize the way classical LMs adapt to different languages and domains.
- Our goal is to create a group of domain-adaptive pretrained models, each specializing in a unique language, through the application of Mixture of Experts (MoE) in our Domain Adaptive Pre-training.
- This approach will enable us to leverage the strengths of individual models, enhancing their performance across various domains.
- We are pushing the boundaries of current techniques, seeking to create a more efficient and versatile modeling strategy for LLMs.
Project Baarat is an open-source initiative to leverage the power of LLMs on Indic-NLP tasks. We aim to build Continually pre-trained, Task Specific Language Models in a Mixture of Experts (MoE) setup. We plan on making a multilingual and cross-lingual LLM that is :
-
Pre-trained on a large text corpus containing various sources of knowledge including crawled wikipedia articles, textbooks, news, social media sites, magazines etc.
-
Fine-tuned on different downstream tasks. We first train a 7B LLaMa-2 model on a text corpus in the target language and save it as a base model. We have considered the following tasks as downstream tasks that will be incorporated in the fine-tuning process:
- Machine Translation
- Mathematical and Logical Reasoning
- Question Answering
- Instruct Fine-Tuning
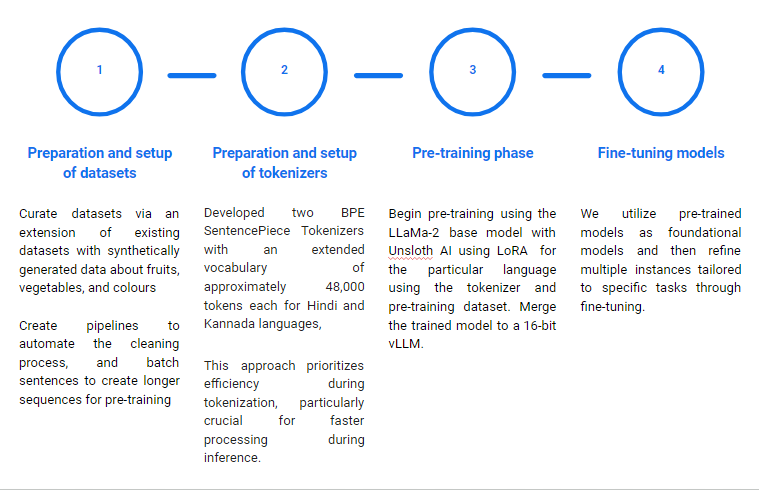

- Tokenizers for Indian Languages: Robust tokenization tools tailored for the unique structures of regional Indian languages.
- Fine-tuned Language Models: Leveraging the power of Large Language Models (LLMs) fine-tuned for Indian languages to understand and generate text with high accuracy.
- Collection of models and data: Completely free and open-source hub of datasets , models, all leveraged into a single python module with documentation for easy usage.
- High Quality Datasets: Take a look at our suite of cleaned datasets ready for your own downstream training purposes.
https://github.com/asphytheghoul/Baarat
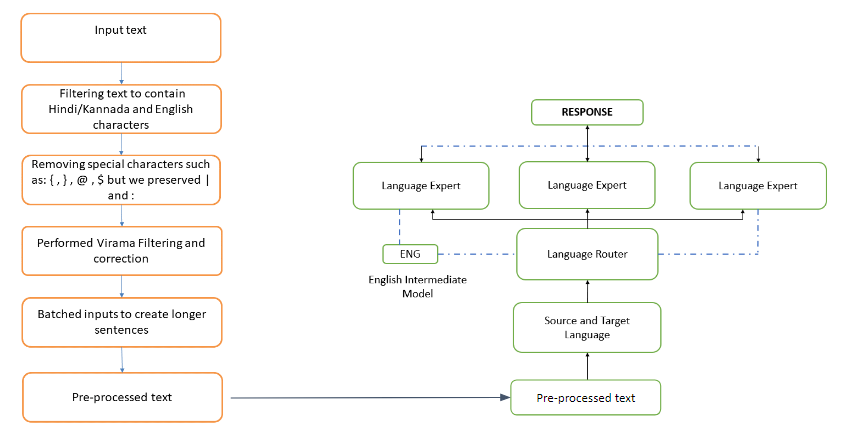
Here is the link to our presentation : https://docs.google.com/presentation/d/1in4MhQkY6N5SnO-PJ9OVhVIe9K6jOXLRrU45GJbNPF0/edit?usp=sharing
This is the link to our project video demo :
https://drive.google.com/file/d/19YY1dBt0t29NtIZGjQsZivuKwfy9IOkC/view?usp=sharing






{{ gettext('Login to leave a comment') }}
{{ gettext('Post a comment…') }}{{ errorMsg }}
{{ gettext('No comments posted yet') }}