LinkedIn maintains large data lakes for various services and applications. The practice described here uses a mix of proprietary technologies and tools, and processes to ensure compliance with GDPR’s user data deletion requirements.
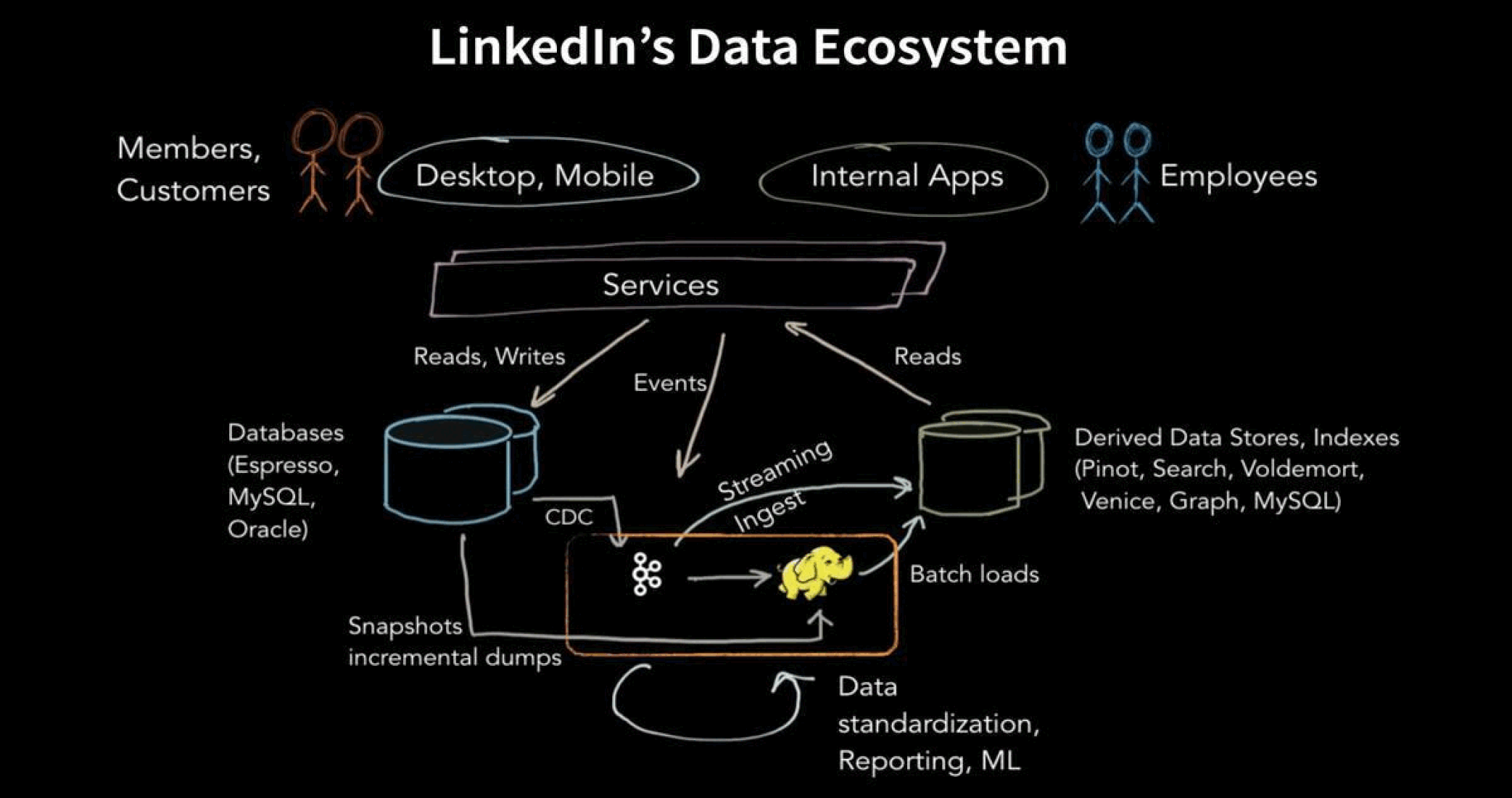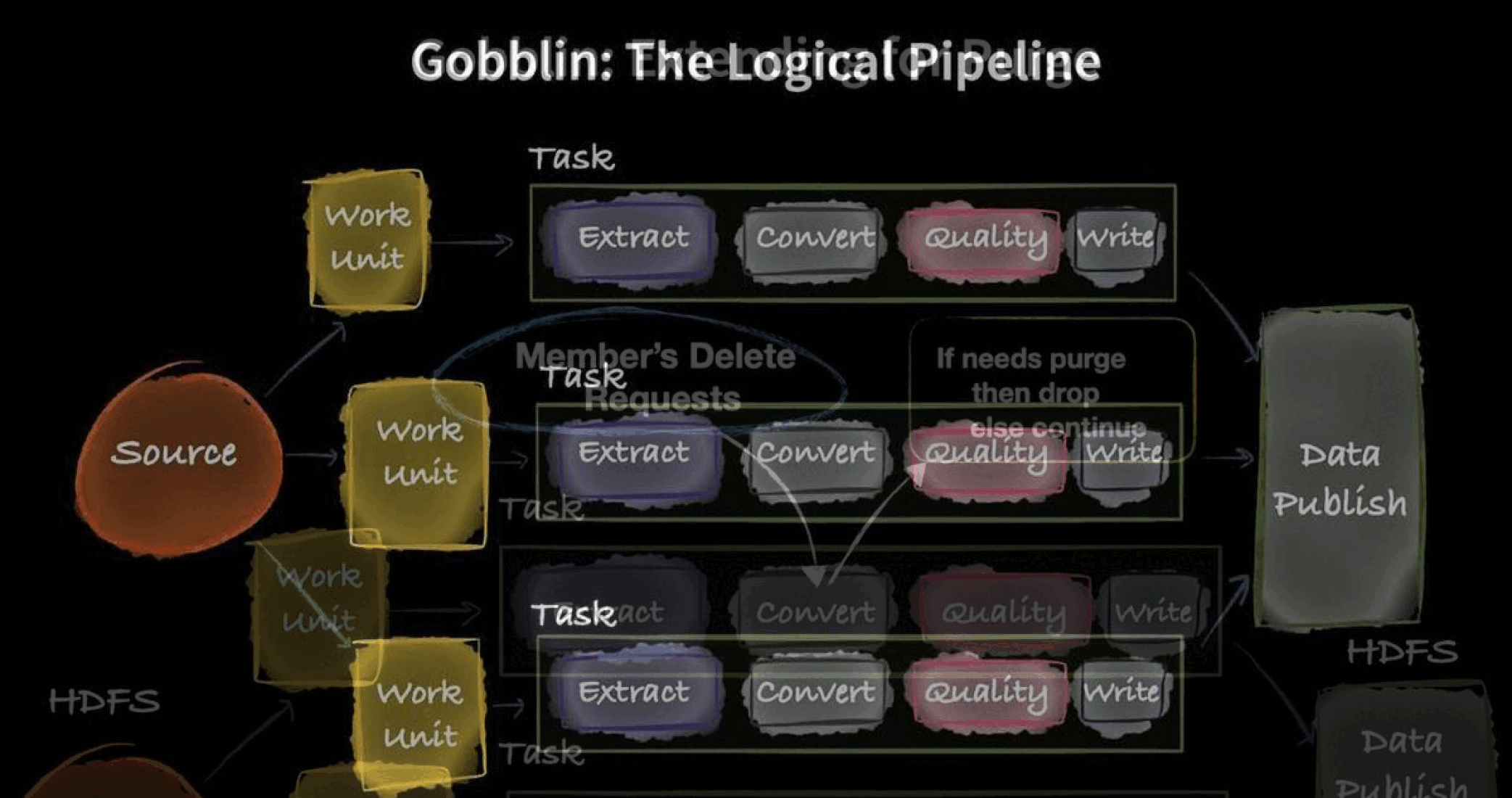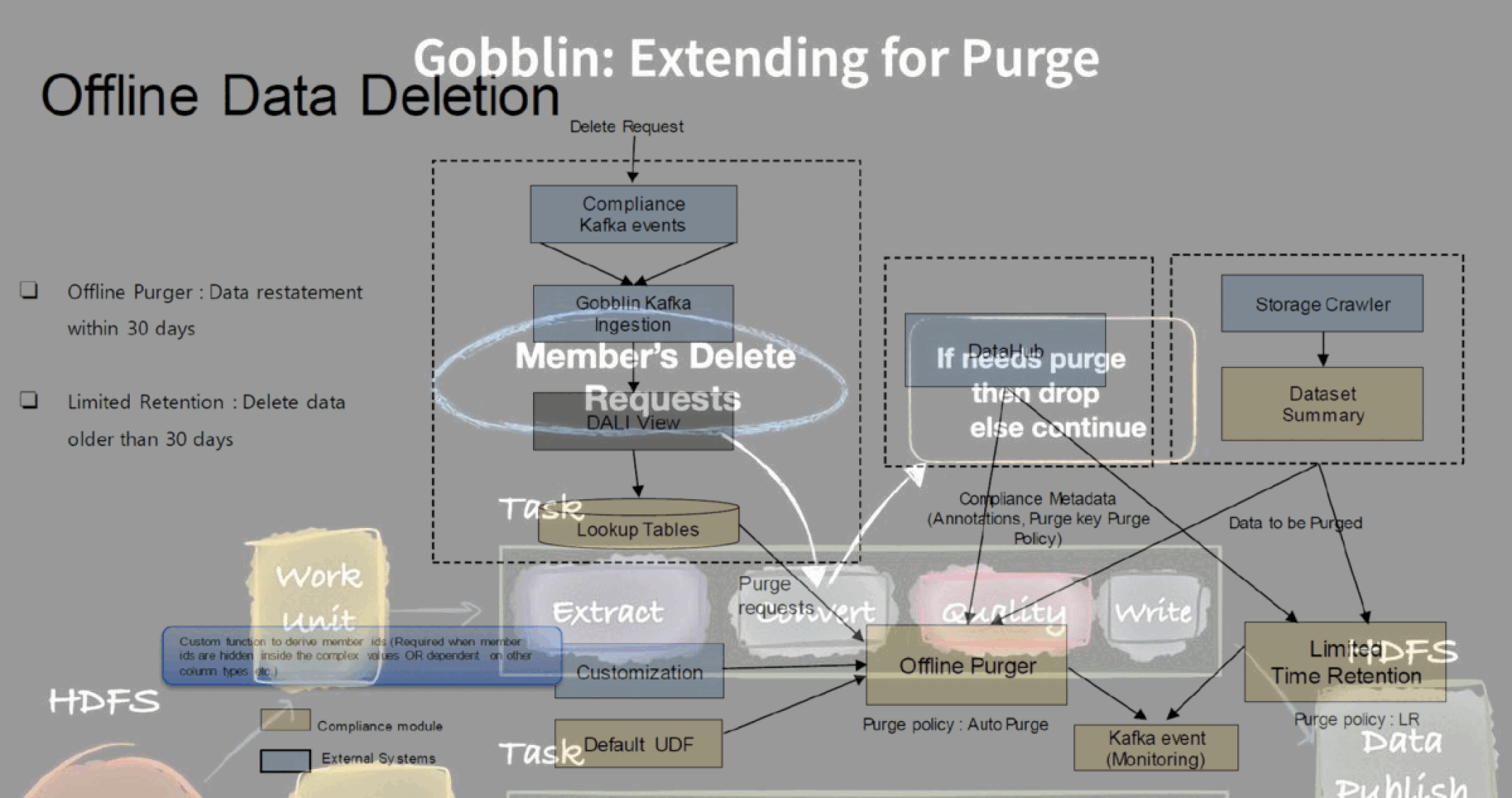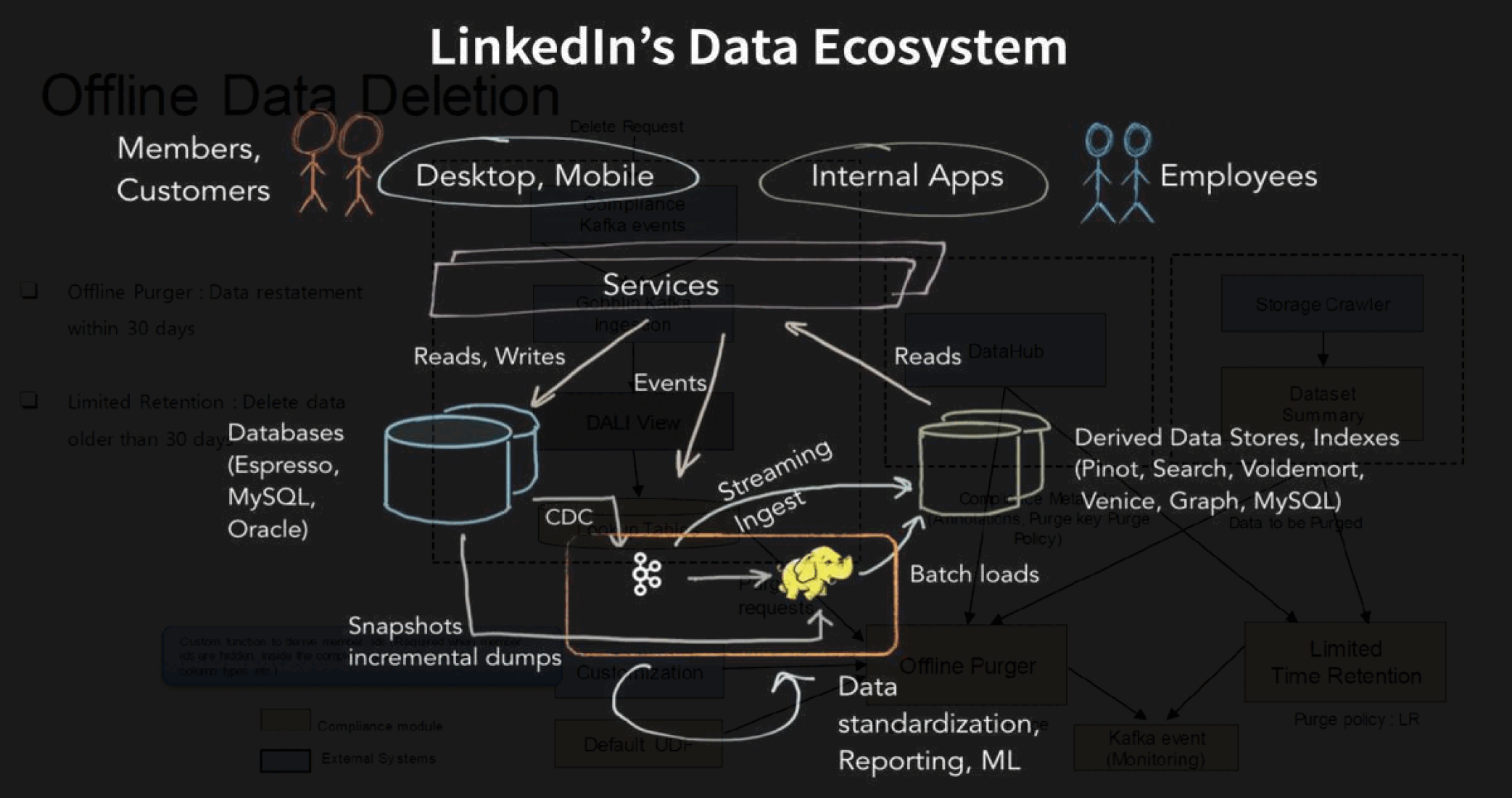
LinkedIn uses an open-sourced data unification service/tool called DALI - Data Access Layer at LinkedIn, and an open-sourced technology called Gobblin to read and process user data. Access to the data is also determined by a layer called DataHub, which is a repository of all meta-data.
Services are performed based on requests, and will involve the DALI, Gobblin, and DataHub. DALI and Gobblin are used by LinkedIn to do
- ReadTime Anonymization of PII
- WriteTime Anonymization of PII
- Data Transformation of user data
- Data Deletion/Purging of user data
Terms/Glossary
- DALI: Data Access layer at LinkedIn - a layer that sits on top of the HDFS and unifies all data access that comes into the lake
- Gobblin: A data - transformation/reading tool that can read data from any source, extract the data, transform it, and write the transformed data to any destination
- DataHub: Cache of all schema meta-data about all datasets that exists in the data lake
LinkedIn captures about 50 categories of Personally Identifiable Information (PII) from each user. User generated/inputted data, automated data collection, and derived data based on the previous two categories: These could be name, age, addresses, job history, IP addresses, device information and more, products/marketing information. These are then used to perform a range of tasks - including suggesting networking leads, job leads, and more.
The data is accessed by three major ‘clients’:
- The User
- The LinkedIn employee
- Third Party services/tools
For LinkedIn, data exists in three stages: online data, or data that is currently in use and being accessed, offline data that exists in the data lake, and data in motion in nearlines/pipelines. Each client may access this data/read it in different ways. Semantics vary across use cases.
LinkedIn has to solve two problems. The first: - PII must be anonymized and access limited, but user data needs to be accessible to community/third party services for providing other benefits and services on the LinkedIn platform.
The second: When a User Data Deletion request comes in. User data, offline and online, near lines and pipelines as well as derived data and data accessed by third parties must be deleted simultaneously.
Both these tasks will need to be optimized for scale - LinkedIn currently is operating at an Exobyte scale of data. TO create offline clusters of anonymized user data available to third parties will more than double the data footprint at LinkedIn. At the same time, it will slow down LinkedIn’s own platform capacity.
To solve this, LinkedIn has developed in-house technologies: the DALI, Gobblin and the DataHub - along with open-source technologies Apache-Kafka (also developed in LinkedIn and opensourced), HDFS and Hive LLAP to optimize these processes.
ReadTime and WriteTime anonymization is one process by which LinkedIn optimizes PII anonymization and makes it available to internal and external clients of data.
LinkedIn creates a Lookup Table (LUT) on the DALI layer, with the user name, and inputs a ‘Compliance Line’ - with details of what category of data is required to be transformed. The LUT is then ingested into the Data Lake using the inhouse tool Gobblin, which then performs the required transformations - in this case, anonymizing the PII.
A similar transformation process is followed when user data deletion request comes in. The LookUp Table is created and ingested into the data lake and Gobblin performs the required transformation - which is purging the row/record.
Once the row - user data - has been deleted, the LUT is cached and the data purged.
A similar process is also performed when user requests specific actions: such as not having data visible to hirers, advertisers and third party services on platform.
The LUT will then be created and the ‘Compliance Line’ will only ‘purge’ the data to identified ‘Clients’ - third party services. This transformation happens in the nearlines/pipelines, and in online data.
The DALI reader thus becomes an abstraction layer to filter the data according to requests.
“If you take any DBMS system, know how the partitioning is done, how the data is read on your disk, how the statistics are collected, where the stats are stored, how the data is laid out on what data structures are used to access your data is sort of abstracted if you look at it, right. All that the end user is cognizant about is their existing database. And there exists a table and all the low level details are abstracted from the end user. So, the end user always gets a view of a DB and the table as a row and the column format. And that’s exactly what DALI is trying to abstract or unify for us.”
Tech stack/Tech solutions:
Hadoop/HDFS
Apache Hive / Hive LLAP
Apache Kafka
RDD/Spark





{{ gettext('Login to leave a comment') }}
{{ gettext('Post a comment…') }}{{ errorMsg }}
{{ gettext('No comments posted yet') }}