This guide details services and security best practices that can be used in AWS. There are three primary aspects to ensuring security in an AWS account. The first is the account itself. The number of accounts being created, ensuring access controls, separating duties, and securing the root account are some of the essential processes that need to be kept in mind. AWS Identity and Access Management is the service that helps one achieve this.
Once the account is secure, the next step is to secure data. Having knowledge of the type of data and where it is stored is important to know whether any sensitive data is being stored and where. Following this, one can encrypt data in use, data at rest, as well as data in motion. AWS provides a set of services to support encryption of all these types of data.
Securing one’s network is the third aspect to securing one’s application. AWS provides services to filter and have visibility over one’s network traffic. One needs to delete the default Virtual Private Cloud, create their own, and segregate roles. To protect one’s network, AWS Web Application Firewall needs to be used.
After securing one’s account, data, and network, applying detection maturity practices is what enables them to avoid data breaches. These practices include:
- Native Logging and Monitoring
- Centralized Logging
- Event Correlation
- Threat Hunting
- Deception
Terms/Glossary
- IAM: Identity and Access Management
- KMS: Key Management System
- VPC: Virtual Private Cloud
- SSO: Single Sign-On
- WAF: Web Application Firewall
- DB: Database
- PII: Personal Identifiable Information
This guide details mechanisms and controls that AWS has developed to achieve desired security postures for workload that is running on AWS. These best practices will help one secure their account, data, as well as network on AWS.
The first thing that one builds on AWS is creating an account. This account provides administrative capabilities for access and billing and one can use it to create and manage AWS resources. It’s essentially the first border or the first guardrail that needs to be thought about from the account perspective.
Some of the best practices that need to be followed are in terms of segregation of duties. Separation of duties starts from the account level perspective. So, one needs to have a clear plan when they are starting off on how to structure your workload from an account perspective. AWS Organizations provides a set of services that help you define account structures and create necessary guardrails. Many breaches that have happened could be blocked by a service control policy within accounts. This can help prevent breaches before they even happen.
Three fundamental things are important once an account is created and logged into:
- Permission management: AWS Identity and Access Management (IAM)
- Data encryption: AWS Key Management System (KMS)
- Network Security Controls: Amazon Virtual Private Cloud (VPC)
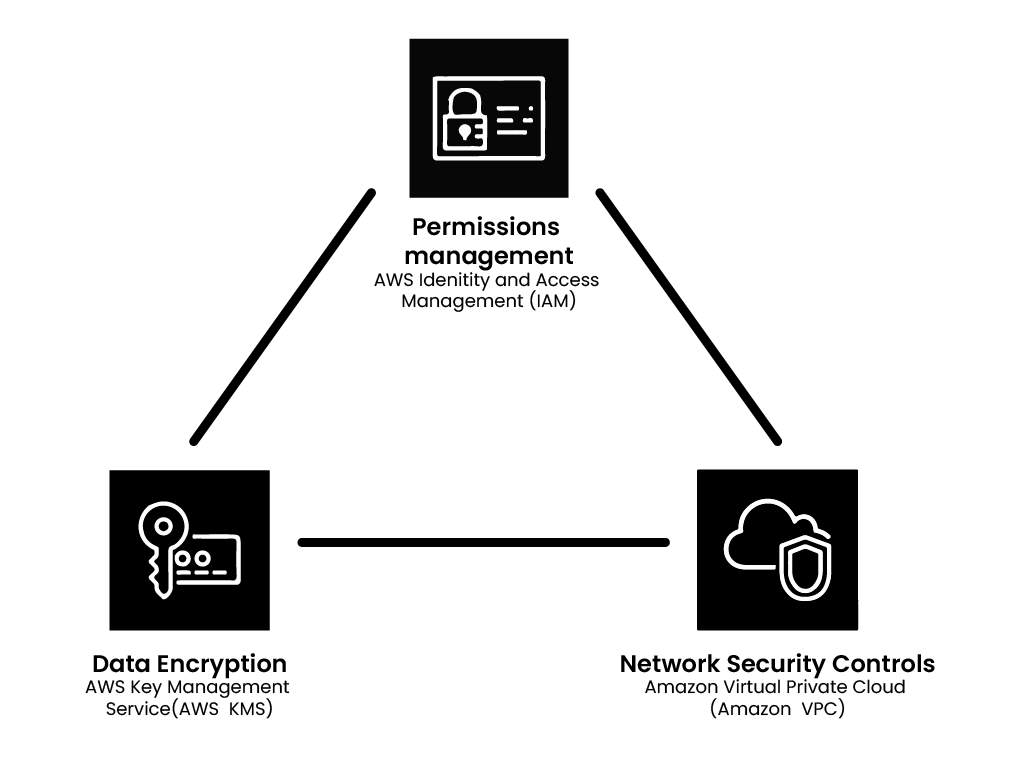
Having multiple identities in AWS Organizations can be a cause for over permission or mispermission. It is recommended to use AWS Single Sign-On (SSO). AWS SSO as a service has an inbuilt directory service and it is free of cost so one can use it to manage credentials. However, having multiple identities in AWS SSO and IAM requires a little discipline in terms of when one creates users, how will they access those users? The good thing about SSO is that it lets one create temporary tokens. This takes away one of the attack vectors, which is long term credentials. Even with multiple accounts having both the strategy in place, one needs to minimize the number of IAM users and have all the users who are on-boarded from SSO.
Securing the root account is extremely important. One’s root account should essentially be locked out. Billing should also be delegated to an administrator or a separate user should have a separate billing role. Root users should never be used for multi factor authentication. Managing in the case of a permission model is highly dependent on the way implementation happens, such as the number of accounts and their structure.
Once the account structure is defined and identity has been taken care of, the next things to look at are the network and data aspects. About the data aspect, one first needs to think about what type of data is being used, what is important, where it resides, who has access to it, etc. After this thought process is done, one has a better understanding of what data needs to be protected and how.
There are three types of data sets, customer data, application data, operational data, and infrastructure related data. It is necessary to carry out a similar thought process for all these types of data to be aware of what type of data resides where and whether or not any sensitive data such as PII is being logged or is at risk of being breached. One needs to have a common framework for logging data as this makes correlation easier.
Once it is known where specific data reside, the next question that comes up is about encryption. The best practice is to encrypt all data, which includes data in motion, data at rest, and data in use. AWS provides different sets of services that can help one achieve this, such as TLS KLBs and endpoints for HTTPS, encrypting data volumes and S3 buckets.
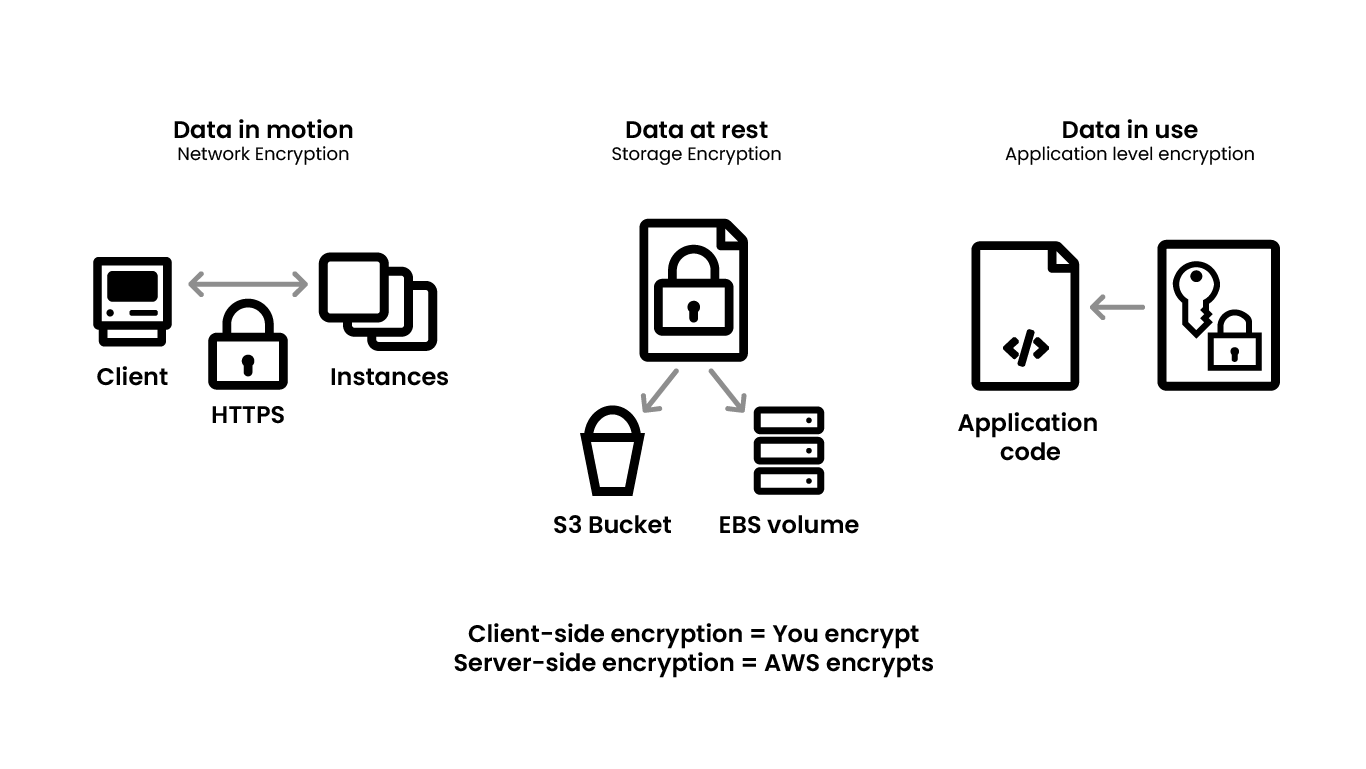
It is often seen that database credentials are stuffed in EC2, which is not a best practice. Implementation rigor is necessary to be able to encrypt different types of data properly. There should be a red team that looks at whether PII data is being logged, credentials have been put into an EC2 instance, and other practices that may lead to data breaches.
Another important thing is that people tend to get confused in terms of server side encryption and the use of KMS. When one is looking at defense in depth from a data perspective, access control should be done from a role perspective, and data should not be accessed directly. There should be policies in place for data access in S3 VPC endpoint, S3 bucket, as well as KMS. The same goes for databases that are being used.
Misconfiguration of route tables is an issue that comes up in numerous discussions. Once the route tables have been looked at, all the traffic should go internally and not out from the internet. Having bucket policies like resource based policies and identity based policies can help achieve this.
With server side encryption, data at rest is encrypted. If for any reason the key gets compromised and a user gets access, what they get is the actual data since it’s encryption is rest. But while retrieving it, it’s decryption gives me the data. And that’s where the power of using KMS based encryption lies. As a best practice, one should separate out the roles from an IAM roles perspective, for who has access to the decryption keys in a KMS. So, if there is ever a breach, attackers will not have access to the encrypted data. Here too it is very important to talk to the teams and separating duties, where users have separate encryption keys and there are very strict rules on who can decrypt data.
When one wants to access an AWS service, they shouldn’t keep the keys in their local environment. They can use an SSO, get a temporary token, connect it to the Secrets Manager, pull the data, and then use it. So that’s data in use. Another thing that can be used are DB credentials. The third is when one’s using data in use. If they are dealing with PII data a lot and have got database column level encryption, they should decrypt it only when they need it in their application logic. Extracting decrypted data reduces security. To use this data, they must take it into memory, add in application logic, connect it to KMS, decrypt it, use it and destroy it.
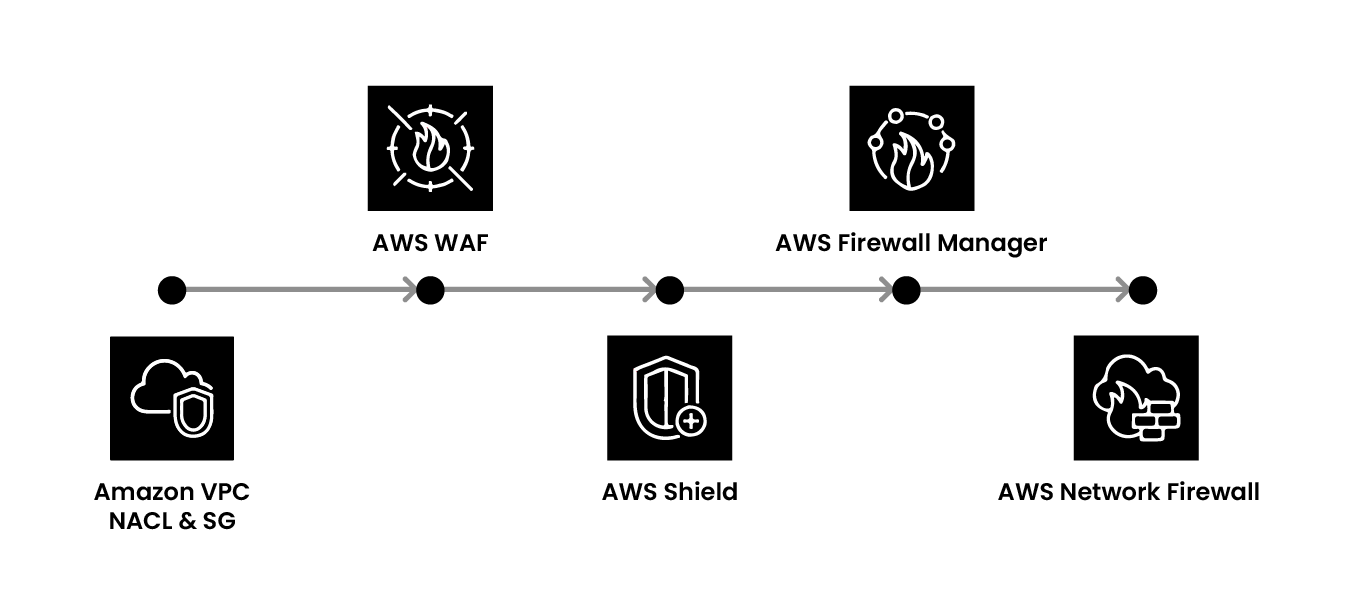
The third aspect to look at is network security which involves filtering and having visibility over network traffic. The first step to this is VPC design. There are two parts to this. When it comes to productions, one should delete the default VPC and create their own VPC. It should have a very clear network architecture of how one wants the traffic to flow. There must be separation of duties from a production, development, and test environment. Once that is done, have clear segregations of security groups and ACL etc. Once they are created, permissions should be removed from an IAM for anybody to go and change it. And if it is an organization, it should be blocked at SAP level. Once this is done, the base architecture is ready.
Now, to protect your network, AWS provides a set of services known as AWS Web Application Firewall (WAF). While WAF is deployed, AWS gives one a set of standard rules that covers some of the best practices. It also takes care of cross site scripting or SQL injection. But essentially WAF is also about having a mechanism where one has some rules to block traffic that is not considered normal from the application perspective. It is important to observe which kinds of URL patterns look normal and which look fishy and then create a block over there.
Another area is where one gets a lot of zero day vulnerability from application perspective. While checking vulnerabilities in the DevOps pipeline, even open source libraries can have vulnerabilities leading to breaches. One can use WAF for vulnerabilities that need to be blocked. WAF is not a set of default rules that one needs to understand the application and usage pattern.
WAF is at layer seven of defense and if one wants a higher level of defense at DDoS attacks that happened at layer 3-4, AWS Shield should be used. Following this, there is a firewall manager that manages all the rule sets for managing WAF rules, the security group, etc.
If one needs to do a Deep Packet inspection, in some of those use cases they can use the Network Firewall. One can import some of the open source rules and then look for any specific signatures or patterns that they want to put as a guardrail in their network traffic. This is essentially what is available from a network protection perspective.
Once the account, data, and network protection measures are in place, detection maturity is the next step. There are 6 processes in detection maturity:
- No Logging
- Native Logging and Monitoring
- Centralized Logging
- Event Correlation
- Threat Hunting
- Deception
The first aspect of this is avoiding logging. This is where people have to spend some time within the organization and go application by application. This is important because one may have centralized logging but all applications need to be on-boarded onto the application logging infrastructure. If they are on-boarded, the next questions to ask is if data classification has been done and whether there is a common log format structure which can be used to find anomalies. Having VPC flow logs, Cloud Config, and other systems in place can help one monitor and detect any configuration changes which will return a metric in terms of utilizations.
Once the organization is at this level, the next thing to focus on is the role of the red team. They need to understand what normal looks like for the application, do threat hunting, and understand the user journey. Only when they know what normal looks like will they be able to create baselines and look for anomalies. They will also be able to identify what is an Indicator of Compromise (IOC). Using this understanding, they can build a library of IOCs, using which they can go through different mechanisms to see if there is any vulnerability and fix them.
The last aspect of detection maturity is deploying deception technology which involves knowing how many log lines is one able to correlate and analyze. This is important because it gives one a single view of different log lines that can come in. There are log lines coming in from instances, CloudTrail, flow log from the network, etc. AWS has services that move into guard duty, which involves network intrusion detection and machine learning to identify anomalies in your account.
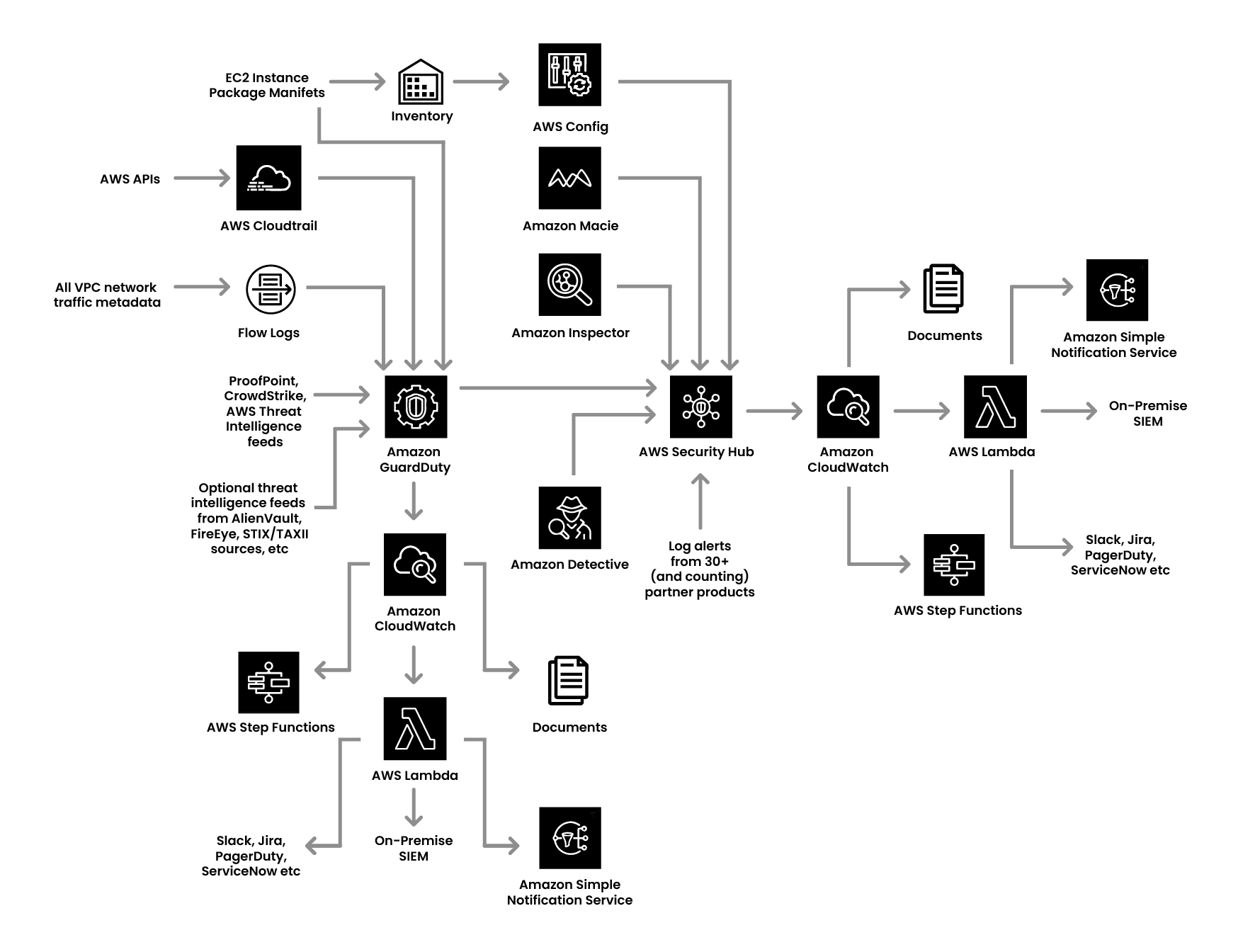
If one has got AWS Organizations, they should enable it at the organization levels, so that it gives them visibility across the account. Use the set of services that feed into AWS Security Hub, such as Config, Macie, Inspector, Detective, etc. Another important thing is that there are multiple third party or ISP products that have a standard logging format that feed into the Security Hub, which essentially gives one the ability to correlate, aggregate, and build the alerts based on CloudWatch.
With multiple log lines, detection can only happen of what one is logging in. Each log line has its own relevance in terms of which areas of compromise one wants to look at, and then correlate and act on that. This is where one will have an automation of how they want to identify a breach, respond to it, and the time required to respond.
There are two separate parts to keeping data in one’s RAM encrypted. One is loading the encrypted data from the database into the memory. The second part is having isolation within the instance itself.
To do SSO from one account to another account, a very clear control of who can log in is required, because making a cross account requires trust for that particular role. And this is done only for a select few roles and the developers who are using it. The role too has got a very clear boundary. One could lock down access to the specific services and geographical regions where developers need access. One can have a different set of rules defined depending on the developers and what they are working on.
To protect their own customers, AWS provides alerts if they detect keys lying around sources like GitHub, but it is recommended that the best way is to put it in one’s own checking process as well. All one needs to do is put a Git Hook, in which they write an expression that looks for a key and then aborts the commit.
Tech stack/Tech solutions:
AWS Organizations
AWS Identity and Access Management (IAM)
AWS Key Management System (KMS)
Amazon Virtual Private Cloud (VPC)
AWS Single Sign-On (SSO)
AWS Web Application Firewall (WAF)
AWS Shield
AWS Network Firewall
AWS Cloud Config
AWS Security Hub
AWS Macie
AWS Inspector
AWS Detective
AWS CloudWatch
AWS Secrets Manager
Git Hook




{{ gettext('Login to leave a comment') }}
{{ gettext('Post a comment…') }}{{ errorMsg }}
{{ gettext('No comments posted yet') }}