Sensitive Information can include information apart from PII. Information can become sensitive based on the context. Appsecco’s client had an application that was logging Sensitive Information and developers had access to those logs to carry out debugging and development. However, they had no use for the Sensitive Information.
In order to restrict developers’ access to Sensitive Information in the logs, LogStash was used to mask data. Logs were sent to LogStash, where Sensitive Information was masked before the logs were sent to Elasticsearch and then Kibana. The developers access the masked logs from Kibana.
This solution enabled the developers to continue their work while the solution was being implemented. The developers didn’t have to refactor anything since the configurations were done in Ops. This solution could be applied to other applications with changes to the configuration to mask what constitutes Sensitive Information in that specific application.
Terms/Glossary
- PII: Personal Identifiable Information
Appsecco’s client, which is a B2C Internet Unicorn, had an old application that was logging some PII and Sensitive Information. The developers had access to those logs, because they needed it for debugging and development. The issue that they had was that they wanted to remove such Sensitive Information from the logs as developers do not need privileged information about end users and clients.
The solution provided was performing data masking on the logs using LogStash. LogStash is a tool that can be used to move, mutate, filter logs, before they are sent to the destination. It is a component of the popular data ingestion system ELK, which is Elasticsearch, LogStash and Kibana. It consists of three segments, which are input, filter, and output.
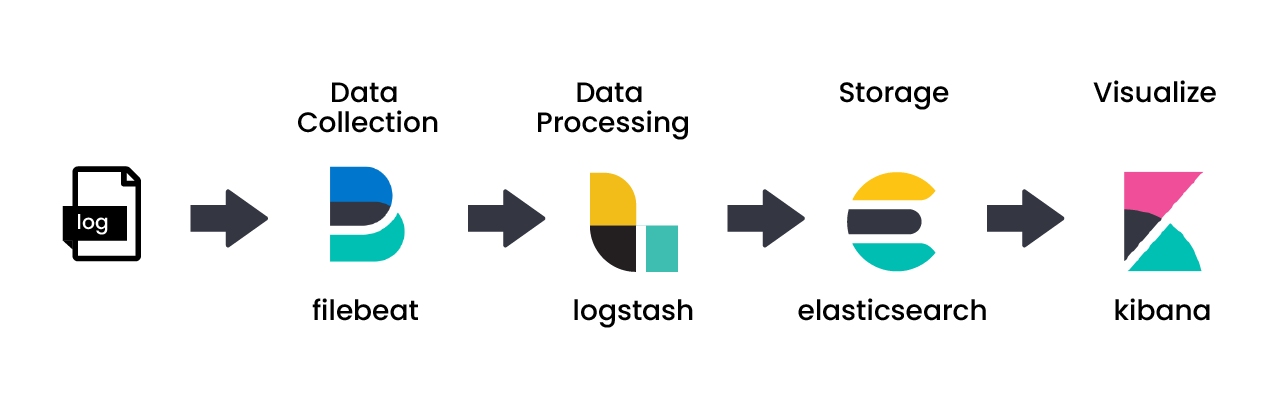
Input is the different segments that send logs to LogStash and output is the output source that LogStash emits to. This could be Elasticsearch or the terminal console as well. The filter was configured to selectively figure out which fields to mask, whether they existed in the log entries being looked at, and then mask those particular kinds of data.
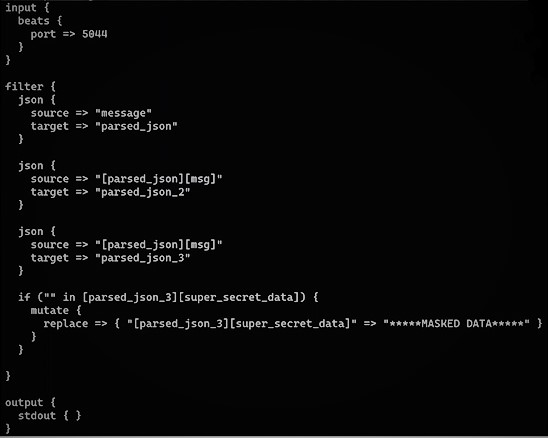
The source is a simplified JSON when it comes to LogStash. This is first converted to two other entities or fields in the LogStash entry, which here is parsed_json_2 and parsed_json_3. At this time, LogStash is running and waiting for logs to be sent to it. Logs are added to Filebeat, which are then sent to LogStash.
Log entries have a key called message and the message contains another Stringified JSON. Stringified JSON is converted into an actual JSON entity using parsed_json and keys containing Sensitive Information are masked.
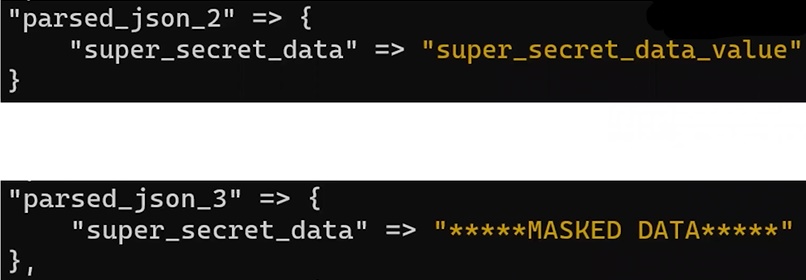
Masked data is replaced with a different value, as can be seen in parsed_json_3 here. This is done to maintain the log structure. Logs where sensitive data is masked is what the developers will be able to view.
There were three impacts of this solution. The first is that developers did not need to refactor anything and the privacy issue was solved without having the developers do any additional work. Configurations were done on the Ops side of things. The logs went to the LogStash session where data masking was done, which was then sent to Elasticsearch and Kibana. The developers get to look at the logs once they are at Kibana, and hence are cut off from the source logs.
The second impact is that this solution can be applied to other applications in the ecosystem. Depending on the context, Sensitive Information can vary and the configuration would have to be altered to mask specific entities that are considered sensitive in that application.
Developers weren’t blocked from doing their work during the time the problem was being solved and this was the biggest impact.
A common question is why was such Sensitive Information being logged in the first place. Since the information was already being logged, changing it so that the information isn’t logged in the future would have taken a longer duration to achieve. While it would be ideal to not log any Sensitive Information, it would be more tedious to do and can be tackled at a later time. As the problem has been solved for now, there is no immediate requirement to stop logging this information.
Another potential issue is that since the original logs still have the Sensitive Information, how does this solution solve that problem? This issue is solved by doing access controls. Developers do not have any access to the original logs that get sent to LogStash or even the computers that run LogStash. The only place they have access is when the masked logs reach Kibana and the developers use it for debugging and other development purposes.
Eventually, different kinds of applications were added to this system. These applications would send logs to CloudWatch from where Appsecco fetches them. And then it goes to Elasticsearch and the masking happens in LogStash centrally for all the computes instead of doing it in the background on Elasticsearch. This is because filtering in the central LogStash space is better than adding configurations to Elasticsearch, otherwise one has to maintain access to Elasticsearch.
LogStash is resource intensive. Since the logs are structured, it enables one to identify fields directly which makes the process much easier. However, it’s not as extensive as regex matching for different fields. As it is a resource intensive application, depending upon the scale, one would scale up the instance that’s handling LogStash as well. The solution that has been provided here is more of a placeholder solution.
Performing reduction operations on the PII data, such as hashing digest, is not as useful when implementing this solution. LogStash has an extensive set of plugins, including hashing plugins. So, to perform such operations, one just needs to write a hashing plugin and the configuration for it. The setup steps are similar, but eventually it will become intensive and complicated.
Tech stack/Tech solutions:
Filebeat
Logstash
Elasticsearch
Kibana
CloudWatch




{{ gettext('Login to leave a comment') }}
{{ gettext('Post a comment…') }}{{ errorMsg }}
{{ gettext('No comments posted yet') }}