This guide talks about data governance and implementing privacy controls. Since developers are not exposed to the full lifecycle of the product, blind spots such as the following can hinder the implementation of data privacy and practicing privacy by design:
- Unstructured Data
- Inventory of systems that store/process/transmit data
- Masking / Tokenizing / Anonymizing / Encrypting
- One cannot protect an organization if they don’t know the exposure of that organization on the internet
A common mistake that developers make is that they interchange the definition of masking, tokenizing, anonymizing, and encrypting the data. When masking specific data, they are often inconsistent in the data they mask on different platforms. For example, the way data is masked on a website may be different from the way it is masked on the app for the website, and this causes privacy issues.
Tokenizing should be done when one wants to rebuild a data set whereas anonymization should be done when they only care about the data structure when capturing data. Developers also often encode data instead of encrypting it, and write their own encryption routine, both of which are not recommended.
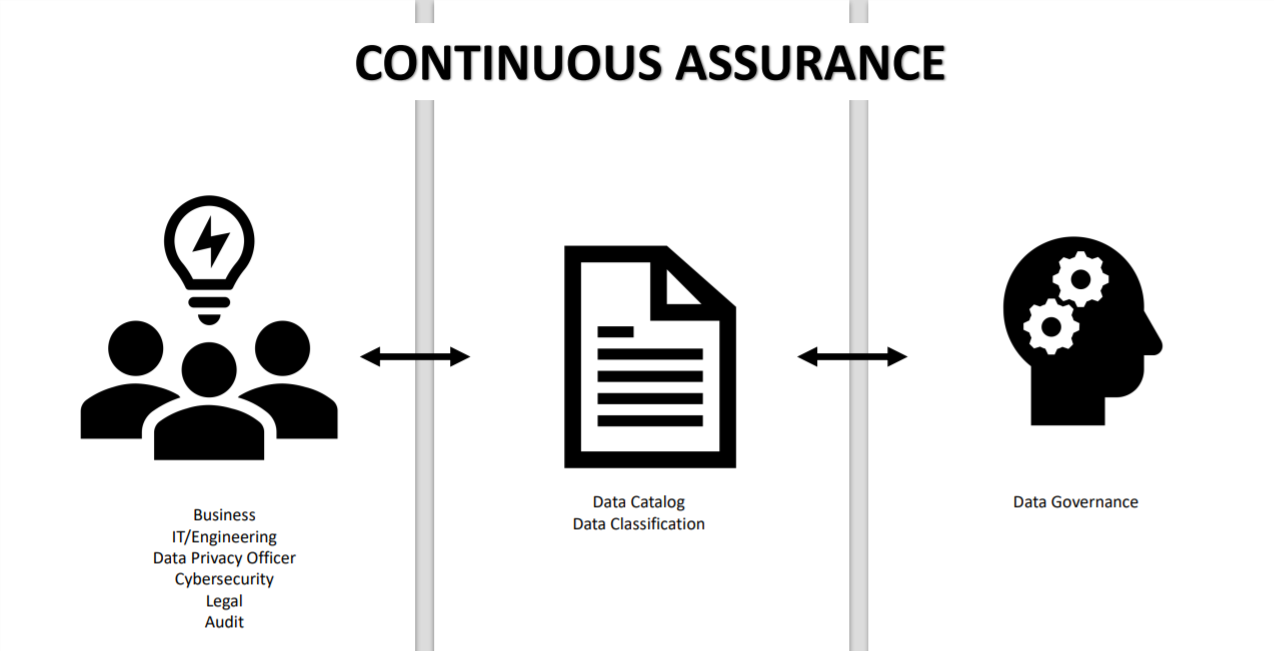
One way to ensure that data governance is continuously practiced in one’s organization is having an autonomous team that consists of representatives from different parts of the organization to come together and carry out data cataloging.
Here are some data governance lessons:
- Catalog privacy related data
- Discover privacy related data in existing systems
- Don’t store data one doesn’t need
- Define technical controls to protect sensitive data
- Build – Measure – Learn - Feedback - Loop
- Trust but always verify!
Terms/Glossary
- API: Application Programming Interface
- DB: Database
- RDBMS: Relational Database Management System
- SSL: Secure Sockets Layer
Data governance is a set of principles and practices that ensure high quality through the complete lifecycle of data. If data sits in one particular system, database, or location, it’s fairly easy to come up with a data governance framework and implement the rules. But the real problem starts when one doesn’t know where their data sets are or what the structure is of that data. As a result, one cannot implement a uniform set of rules to make sure that one has data or privacy by design implementations for systems within their organization.
Blind spots when implementing data privacy and practicing privacy by design include:
- Unstructured Data
- Inventory of systems that store/process/transmit data
- Masking / Tokenizing / Anonymizing / Encrypting
- One cannot protect an organization if they don’t know the exposure of that organization on the internet
Unstructured data is anything that does not have predefined data models or schema. Some examples are:
- Sensitive data exchanged over emails, documents, text files etc.
- Sensitive data stored on public S3 buckets
- Data shared on social media
- Data shared indirectly with Suppliers / Partners
The inventory of systems that store/process/transmit data is way beyond RDBMS. Developers are never exposed to the entire lifecycle of the product and since their visibility is minimized, it leads to a lot of blind spots. Poorly designed API’s are common ways of sensitive information being leaked. Full blown data analytic systems that can record entire user sessions in their browsers and give businesses the opportunity to replay the entire session is another big privacy nightmare, if not implemented correctly. Other such blind spots include query strings such as PasswordReset Tokens, support systems, and logs.
Consider a case study for a business requirement of an API that returns all the attributes about a user stored in their DB after successful authentication. Another requirement is that any number of partners can consume this API and each partner needs access to different attributes within that data set.
A possible solution to this requirement is that one creates an API and sends all the user details upon successful authentication. The partners are allowed to choose the fields they want. So, if one has 100 attributes about a given user, there is no problem in giving vendors all the 100 attributes because they’ve signed an NDA. The vendor will in turn end up using only those that are required by them.
This solution has less time to market, less overhead, and a quicker turnaround. Even if one has to make slight modifications, they can just make it in one place and it will be applicable to everybody. The biggest challenge in doing this is that it’s not data privacy friendly. For example, one has a vendor that only needs five fields from the response of the API. But because they’re given all attributes, there is nothing that stops the vendor from iterating through the database and storing all those attributes about the users. This is a potential area of concern for a privacy minded organization.
Another way to solve this problem is to create multiple versions of the API for each partner and send them only what they have signed up for. The biggest problem with this approach is the time to market, which means that if the business follows a lot of agile practices and they onboard new vendors very frequently, then this is going to be time consuming. With every new partner that is onboarded, one has to create a new version of that API and then map the fields that are required. This also means that there’s a bigger overhead and turnaround time. The advantage of this solution is that it is data privacy friendly.
The second potential design is where one creates a single API with multiple views on top of it for each partner. Technologies like Graph QL and Facebook’s Graph API are used to do this. Depending on what the partner ID is, one sends the partner only the data that is required. The pros in this process is that it is a very efficient, scalable, and data privacy friendly process. The only challenge in this is governance and oversight. What this means is that there is no way for one to not know what data is accessed by a given vendor, if one has the right checks and balances in place to review the responses that are sent to individual partners on a periodic basis.
Governance and oversight are fairly easier problems to solve when the underlying platform is foolproof or that it does the job that it was designed for, i.e. allowing one to create views and only exchanging that information that is required. The blind spot that one comes across here is that poorly designed API’s can leak sensitive customer data that was not intended for sharing.
Typical password reset functionalities are designed such that the customer receives an email with a link to reset their password where they have to enter a password reset token and can then reset their password if the token is correct. What happens actually at the back are the privacy implications. Now, the browser security model simply states that anything that one sends in the query string will always be visible and will always be logged by a web server. So for example, one has two parameters that take a username and a password. And if one ever does a “get” with that request, whatever is the fragment of that URL will eventually get recorded as a part of web server logs, which means that whoever has access to your web server logs, could also potentially have access to the password reset codes.
One of the important problems with this approach is that when the page loads, the entire link along with the code will be submitted to any trackers that are implemented on the page. What this means is if one’s organization wants to track user experience or builds a tracker that collects certain information whenever a user visits the page, the trackers will have the ability to inject JavaScript into one’s browser. The most widely used marketing trackers on the internet are through Google Analytics, or other providers on the internet. One should be very cautious about what the tracker is capable of injecting back into the pages.
When one clicks on the Save button, whatever is in your browser URL actually gets submitted as a reference to the next page. From a privacy point of view, there are a number of things that could potentially go wrong here. Let’s say that the password reset functionality was not implemented correctly, which means that once the user clicks on the link, the token or code doesn’t expire. The other mistake could be that if one’s business is very keen and are very keen in terms of making sure that the users have the best experience of these codes, they live for longer than 24 hours. This means that the link will remain active for the next 24 hours even if the user has clicked on the link. This link is then submitted to a tracker and anybody who has access to the tracker will potentially have access to the code links as well. So, as a developer or as an organization, anything that leaves the boundary of systems is out of one’s control and what happens to that data is something that is very difficult to cover. As a result, it becomes very difficult to implement privacy related design controls on such pages.
The blind spot here is that any sensitive data that is sent in query strings will be present in web server logs. These can be leaked via referrer and submitted to analytic trackers if implemented or network device logs.
Unintended data can get captured by the actual vendor, or the owner of the website. All such systems actively talk about a lot of privacy controls that are there in their application, but at the end of the day, one can only trust them for what they say. It’s also very important to verify the claims that are made. Verification could be as simple as integrating the tracker in one’s app and then doing an assessment or a review while actively submitting the data from the app and seeing what’s happening on the other side. Then, one can also find ways of compromising that piece of information or trying to get unauthorized access to that information. This is how one can test how foolproof these technologies or solutions are.
One area where developers are often blindsided is when they try sending data in a query string but don’t know that it is potentially getting logged everywhere where the SSL is intercepted or offloaded. When one has perimeter technologies such as web application firewalls, one needs to offload their SSL onto those devices, so that developers can carefully examine the requests for any potential anomalies. If everything seems good, then they forward this request back to the actual origin server. Very big organizations which give access to their employees for Internet implementing proxies SSL intercept one’s traffic, through which they know everything that is going in and out of one’s system. So, while passing anything that is sensitive in nature, it is important to know that it is eventually going to get logged.
The problem here is that if any of these implementations have any sort of authentication or authorization issues, then one can actually extract that request from one’s proxy and replay it on behalf of the user. If one’s organization or product that is consumed by different people on the internet is under any kind of attack, and one has a web application firewall or a packet capturing device, then they will always be able to see what the attacker is actually doing. They will be able to go through the packets and know the details of the attack.
A common mistake is that developers very easily interchange the definition of masking, tokenizing, anonymizing, and encrypting the data. Encryption does not solve all problems and it may not even be the requirement for a particular use case, but using it will only complicate the system. Similarly, definitions for masking and tokenization are often exchanged.
The most common errors from a data masking point of view is consistency. Say one has an API that is consumed on the web as well as on the app side. They decide to mask certain sensitive information on the web and mask the same information differently on the app. These inconsistencies can introduce a lot of privacy problems. As for patterns, one should use different character sets and try to match them on the client side. So, when somebody inspects elements, they can actually see what the real text is. Masking logged transactions is also important since if financial transaction data is available in clear text, it’s another privacy issue.
Whenever there is a business requirement that asks one to capture sensitive information from an analytics point of view, these are genuine requirements for one to capture the data. The approach should be that when one wants to rebuild the data set, they should always tokenize it, and when they only care about the data structure, they should anonymize it.
Whatever one does essentially goes inside backups, data stores, data warehouse, data lakes, etc. The most common mistake is that developers encode data instead of encrypting it. They choose the incorrect cryptography type. So, instead of using asymmetric data, they use symmetric data and vice versa. This has privacy implications. Additionally, developers also end up writing their own encryption routine, which is not recommended as encryption algorithms have complex mathematical properties.
One can’t have 100% security and 100% privacy. So it’s always a balanced call between what is right, what is wrong, and is where one can draw a middle ground.
An autonomous team consisting of representatives from different parts of one’s organization should come together, and carry out data cataloging. This involves identifying the data that is important from a privacy point of view, and then classifying it. Eventually, this is fed back into the data governance framework. This is a bi directional process. While all of this is always going to be a moving target, continuous assurance is a feedback loop that one is doing the right audits, trying to raise or identify different blind spots through the life of the data itself, etc.
Some open source projects that can be extended:
Tech stack/Tech solutions:
GraphQL
Facebook Graph API




{{ gettext('Login to leave a comment') }}
{{ gettext('Post a comment…') }}{{ errorMsg }}
{{ gettext('No comments posted yet') }}