This guide talks about experiences in the industry with data governance and strategies in big organizations. Over the last few years, types of data have evolved rapidly and in today’s time, there are numerous new tools and technologies that exist.

Managing the security of all the data that exists in these different environments is far more complex now than it was a decade ago, especially since organizations have moved to the cloud.
Data governance cannot fully be measured using tangible metrics, but data security or the lack thereof expose how strong or weak an organization’s data governance framework is. Most organizations lack a clear understanding of compliance laws, the types of data they store, security lapses in their systems, etc. It is crucial for them to first understand these aspects of data security and governance.
There are three main categories of failure that cause issues in data governance:
- Strategy/Vision
- Compliance
- Implementation and Tech Challenges
Issues in data governance strategies can lead to a negative impact on how organizations scale and grow in terms of data, organizational growth, maturity, and people and skills that are available in the organization.
Challenges that need to be addressed for better governance are as follows:
- Organization-wide compliance and policy enforcement
- Cataloging
- Lineage
- Classification
- Glossary
- Metadata
- Distributed workflow collaboration
The first step to creating a good data governance process is by having an initial discovery phase where one builds tools and gives them to teams, which they integrate with the solution they’re trying to build. Following this, they should start introducing compliance and audit. The final phase is a never ending phase wherein data governance responsibilities are distributed among different teams.
Terms/Glossary
- ETL: Extract, transform, load
- ACL: Access Control Lists
- Cataloging: process of making an organized inventory of one’s data
- Lineage: process of understanding, recording, and visualizing data as it flows from data sources to consumption
The type of data sources that existed between the 1990s-2000s were MySQL or Oracle databases and the role of governance in that time was to be aware of all of the tables that existed in data warehouses, along with all of the different fields and the types. Having ACLs and role based access control on databases was sufficient enough as a governance strategy.
Now, the data landscape has exploded to a large extent. There are a variety of new tools and technologies that exist and a lot of organizations are using many different combinations of these tools. There exist a plethora of BI tools, data processing tools, data ingestion tools, and multiple other tools to do data science, visualizations, etc. Additionally, there are many organizations that are now moving to the cloud. This is a huge challenge, particularly in terms of security and infrastructure.
Moving to the cloud has made the data governance and privacy process far more complex, because now multiple different services need to be managed that connect together and form what was a single hosted platform earlier. In addition to this, the data itself is more complex now. There are differently structured data formats, as well as semi structured and unstructured data. This constitutes the entire gamut of data that one can imagine. Given all of this complexity, a lot of organizations have failed to come up with a good data governance strategy.
While one cannot assess organizations on metrics such as quality and other aspects of governance, security puts out the data governance frameworks and strategies that these organizations have embraced in a public view. Many such organizations don’t have a clear or good data governance framework in place to comprehend their data, policies that they should put in place, compliances and the ability to understand them, and whether there are security lapses or issues in their ecosystem.
Without a good data governance framework, most of these organizations tend to miss out on being able to track data sets across the organization. They tend to fail when it comes to creating data ownership and accountability of the data that they’re generating. There is also the issue of data quality and most organizations are realizing now that if the data they have is not of good quality, it will often give them wrong insights and lead to wrong business decisions. This leads to a reduction in productivity for their own teams and they fail to reduce friction between teams.
Without a good framework, teams won’t come to know about the data in the system and most of the time end up building redundant processes. They also fail to have processes in place to get access to the data even when it comes to the internal organization itself. These issues have a direct impact on how organizations scale and grow in terms of data, organizational growth, maturity, and people and skills that are available in the organization.
The main challenges to solve which are typical of data governance at scale are:
- Enforcing organization wide compliance - Having the ability to repeatedly validate whether one is in compliance using semi automated controls is important.
- Cataloging: Having complex AI/ML and ETL pipelines in a catalog gives one the ability to visualize it and be able to understand it better. It also gives one the ability to see how their jobs are set up, how they’re triggered, and be able to optimize the overall flow which may sit between multiple teams.
- Lineage: Lineage gives one the ability to track how their data is being curated and is especially useful if one has very large ETL pipelines and data flow between multiple hops and nodes in the system.
- Tagging and classification: A lot of organizations tag and classify data to some degree to make sense of the data sets that they’re curating. However, their tagging and classification frameworks are not mature. It is important to classify data on the basis of its domain, the owner of the data, and the sensitivity level of the data.
- Glossary and metadata: There are second and third level concerns which can be solved by having a business glossary and custom metatypes. This provides one with the ability to describe and rationalize all of one’s data sets and build on top of what one already has. Custom metatypes help model the different ways in which an organization thinks about its data.
- Distributed workflow collaboration: Different teams with different roles in organizations should work with minimum friction and be aware of the data governance practices in place. Every team should play a part in applying the data governance model while using tools and creating solutions.
- AI/ML: it is often the case in organizations, where there are a lot of complex AI/ML and ETL pipelines that nobody understands to the full degree. Cataloging these pipelines can provide clarity.
- Compliance/audit: There is a lack of understanding of compliance laws which leads to poor data governance practices. Additionally, it is important to have a semi-automated audit process that can validate whether or not an organization is complying with security laws.
- Understanding laws: The first step to creating a clear and good governance process is understanding compliance and security laws. Currently, not a lot of people in most organizations understand these laws properly.
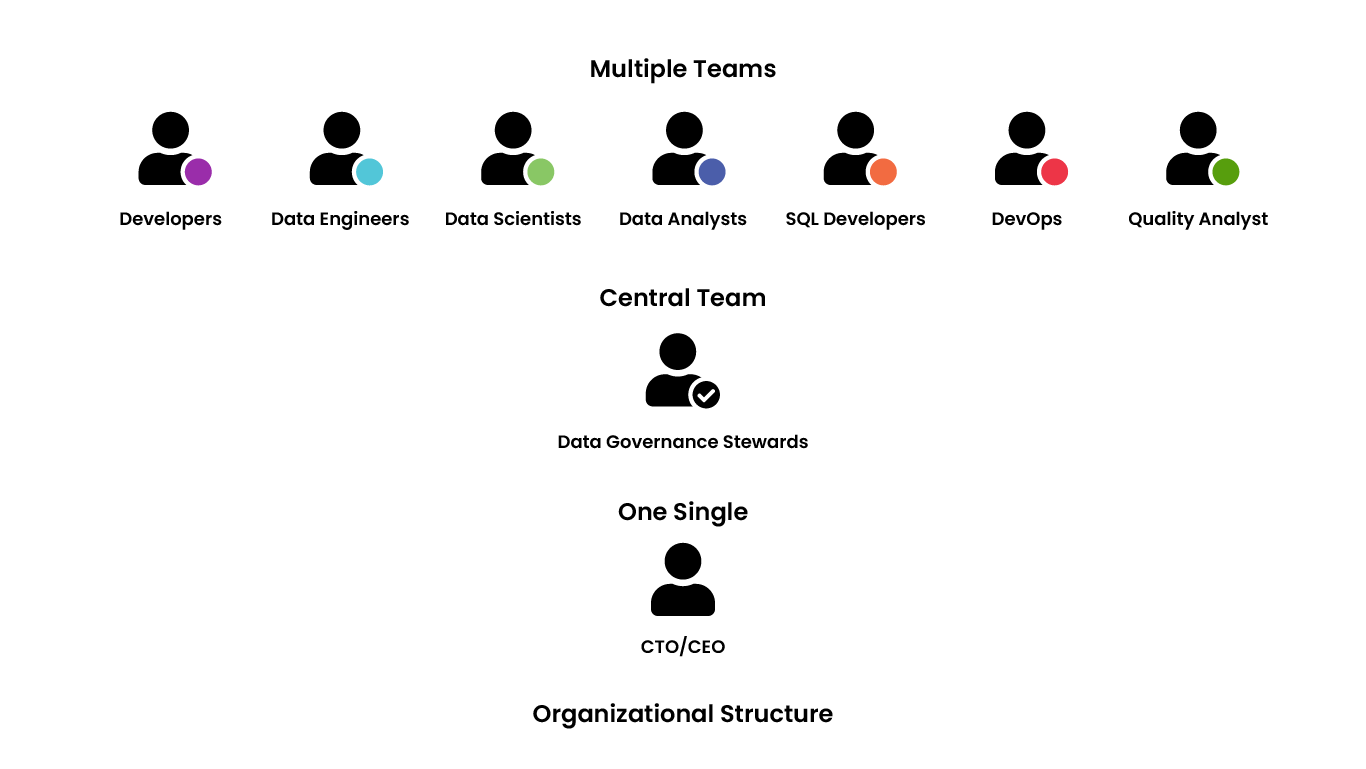
Most organizations use different tools for a lot of different functions. Even among these different functions, there are multiple alternatives. There is a notion of complexity when it comes to the tools and the architecture. But what a lot of people don’t realize is there is also a lot of complexity when it comes to the organizational structure. It is very crucial for all the different roles to function in the best way possible to have minimum friction, be aligned, and to be aware of the data governance framework that has been put together for them. Ultimately, they are the key people who are going to be partaking in the face of the data governance strategy.
Most organizations apart from well-established ones like Amazon and Netflix have low maturity when it comes to data governance. These organizations often don’t understand things like the different sensitivity levels of data, how they should be curating and securing data, etc. Additionally, a lot of organizations try for anonymization frameworks where they want to be able to segregate a particular type of data and be able to say that that data is sensitive when it isn’t. But the anonymization frameworks are limited to doing simple things such as putting certain data in a separate S3 bucket, and people don’t really understand what it means to anonymize and secure anonymized data. So, people think about the access to the anonymized data, but not about the infrastructure and other such aspects.
Such issues fall under three main categories of failures:
- Strategy/Vision: One of the key issues is that people still hold on to a very old way of thinking about data. They often end up thinking about the tools and tech stack that they need, but they fail to think about how they’re going to change the organization and the culture that’s within the organization. So, often they don’t understand these systems internally themselves, and even if they do, they often fail to articulate value to other business stakeholders and get proper funding to be able to move forward with a data governance strategy. And it’s often very hard because most of the organizations are only able to rationalize things when it comes to data security. But what they don’t realize is all of these other capabilities and features of a good data governance framework also define how quickly they can build and how quickly they can mature as an organization. Lastly, most organizations look for a one stop solution, which is not practical.
- Compliance: Thinking about governance solely from a compliance perspective and not focusing on other aspects of data governance is another challenge to effective data governance. Also, since the tooling is not very mature, there are a large amount of tools that one has to deal with. They often end up spreading the security mechanisms across a multitude of tools without a single holistic view of security and auditability in place. Lastly, getting a vendor to fix compliance problems is unhelpful since they won’t be able to provide a customized solution unless they are also involved in building the data governance strategy. So, one needs to work together with their vendor.
- Implementation and Tech Challenges: In terms of onboarding, different teams need to understand why data governance is important. A lot of times people just mandate it which makes these teams lose interest, create friction, and ultimately the business decides not to go with a governance strategy. There is also a lack of skill maturity in the industry when it comes to data governance frameworks. While a lot of people are starting to talk more about it, there is still a long way to go.
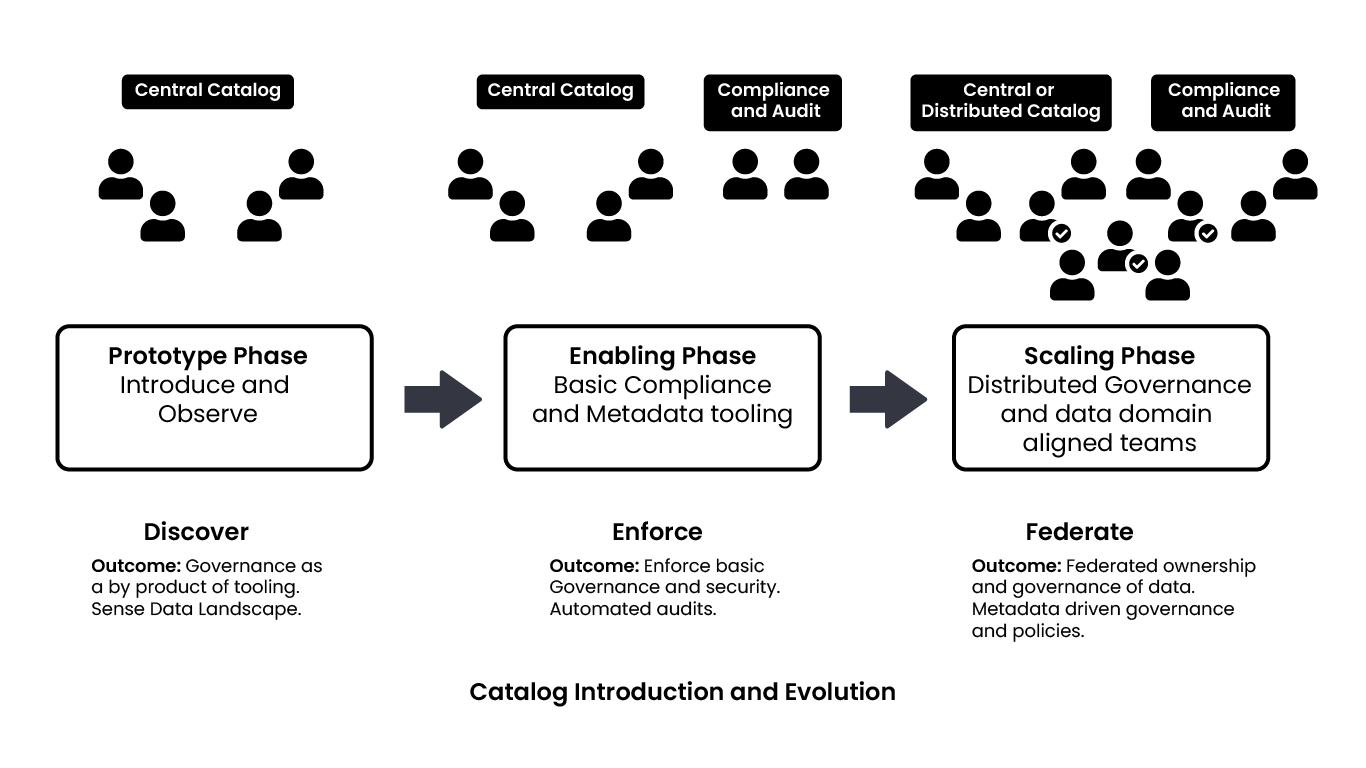
It is important to understand that data governance is a journey, where one should incrementally build it out to avoid as much business loss as possible and to better understand the right strategies to be applied. A good way to start with this is to be able to put a very lean framework together. It is recommended to have an initial discovery phase where one should introduce governance as a byproduct of tooling, by building tools and giving them to teams. These tools should provide one with the data they need. The different teams should be allowed to try to achieve their business goals while integrating tools with the solution they’re trying to build. It is also useful to follow a pull based model and discover datasets.
Once one has a sense of their data landscape, it is useful to start introducing compliance and audit. One should have a separate data governance organization which tries to tackle the problem of understanding the basic minimum criteria of security, audit, data quality, etc. that should be enforced across the organization and formulate rules. The governance framework should continue to be built while formulating these rules. Ideally, a central catalog is what works best in this phase. Here, one should start moving towards a push based approach, where the producers of data curate all of this information into the governance framework. Those who are producing this data should be pushing things like data quality, sensitivity levels, etc. and should start mandating this across the organization. As an outcome, one can expect enforced basic governance and security in place. Additionally, what is useful is building an automated audit system that runs in a CD pipeline where one can get automated reports of compliance, security, and infrastructure, in a single location.
The final phase of building this data catalog is a never ending phase. Data governance responsibilities should be federated to different teams. So, the compliance and audit team should ideally spread out and become part of different distributed data teams, which are responsible for their own data. There’s a data steward and a data governance individual in each of these teams driving these requirements at a team level. This is important because when one starts scaling beyond two or three different teams, it becomes very hard to be able to rationalize about the different tech stacks that these teams are using and be able to understand the context of the domain of the data itself. This is where it’s useful for these individuals to be working directly with the teams rather than chopping things out as a separate entity altogether. What can also be done in this phase is distributing the data, ingestion, and curation ability to multiple teams and these different catalogs curate the data further to a central catalog. In terms of tooling, it is not necessarily as mature when it comes to achieving some of these ideas. However, there are open source frameworks that have come into play in the last one or two years.
Some tools that can be used to automate data governance are a combination of Apache Atlas and Apache Ranger. However, nowadays large organizations prefer to create custom frameworks. One needs to be able to bring in tools that they feel would fit well in their organization and then grow from there, rather than just deploying something and expecting output from day one.
The hardest to do is setting up security and quality controls around the data that organizations are curating. Every team typically goes ahead with their own set of tools, depending on their work. What becomes really challenging is to have tooling that works across all of these tools. It’s very hard to be able to track data across different tech stacks, enforce access control policies, and be able to audit the data that sits across these tech stacks.
Smaller organizations like to keep their security lean and non invasive. A pull based approach is very common here. They use things like AWS Glue and AWS Glue Crawler to curate metadata. They also do not have a lot of these problems because they use a few tech stacks and are not spread all over the place. However, this problem is bigger when it comes to large enterprises because they have data that needs to be secured and have a lot of teams working on these data sets. Different roles, teams, and tech stacks make continuous security much more complex.
Tech stack/Tech solutions:
Apache Atlas
Apache Ranger
AWS Glue
AWS Glue Crawler




{{ gettext('Login to leave a comment') }}
{{ gettext('Post a comment…') }}{{ errorMsg }}
{{ gettext('No comments posted yet') }}