
Shruti-Drishti is an innovative project aimed at addressing the communication gap between the deaf and non-deaf communities in South Asia, particularly in India. By leveraging deep learning models and state-of-the-art techniques, we strive to facilitate seamless communication and promote inclusivity for individuals with hearing impairments. 🌟
Our webapp here aims to bridge the communication gap between the Deaf and Non-Deaf Community based on our LSTM and Transformer model on the sign langauge video keypoints.
Our aim is to improve the quality of communication by providing accurate and reliable translations.
We provide two Services- (1) Real Time Sign Language to Text
(2) Text to Sign Language Translation.
This is the repo: https://github.com/pranjalkar99/shruti-drishti
(Note: The repo is being updated with the latest changes and work done so far.)

-
Sign Language to Text Conversion 🖐️➡️📝: Our custom Transformer-based Multi-Headed Attention Encoder, powered by Google’s Tensorflow Mediapipe, accurately converts sign language videos into text, overcoming challenges related to dynamic sign similarity.
-
Text to Sign Language Generation 📝➡️🖐️: Utilizing an Agentic LLM framework, Shruti-Drishti converts textual information into masked keypoints based sign language videos, tailored specifically for Indian Sign Language.
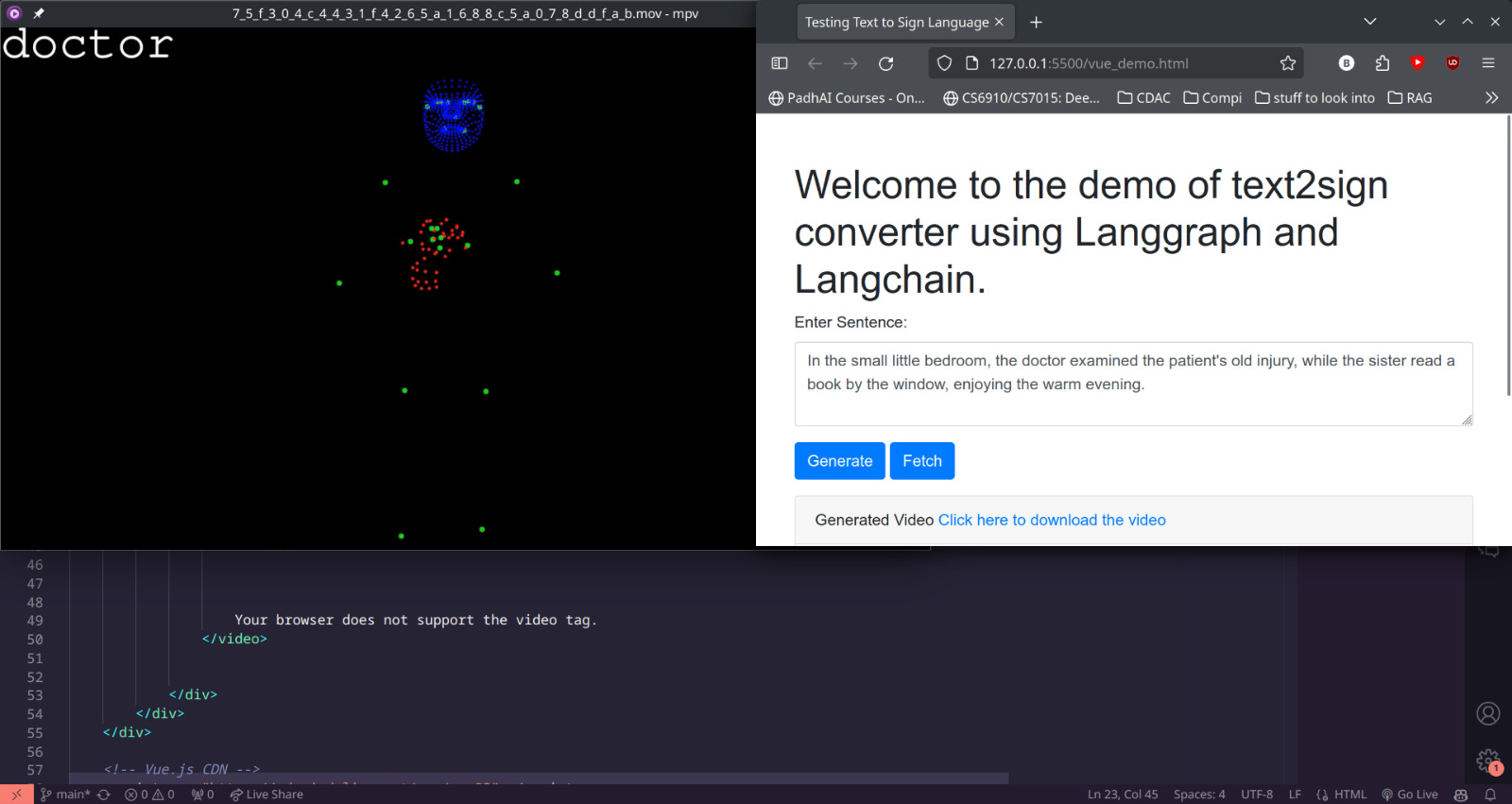
-
Multilingual Support 🌐: Our app uses IndicTrans2 for multilingual support for all 22 scheduled Indian Languages. Accessibility is our top priority, and we make sure that everyone is included.
-
Content Accessibility 📰🎥: Shruti-Drishti enables news channels and content creators to expand their user base by making their content accessible and inclusive through embedded sign language video layouts.
Link to the Dataset: INCLUDE Dataset
The INCLUDE dataset, sourced from AI4Bharat, forms the foundation of our project. It consists of 4,292 videos, with 3,475 videos used for training and 817 videos for testing. Each video captures a single Indian Sign Language (ISL) sign performed by deaf students from St. Louis School for the Deaf, Adyar, Chennai.
Shruti-Drishti employs two distinct models for real-time Sign Language Detection:
-
LSTM-based Model 📈: Leveraging keypoints extracted from Mediapipe for poses, this model utilizes a recurrent neural network (RNN) and Long-Short Term Memory Cells for evaluation.
- Time distributed layers: Extract features from each frame based on the Mediapipe keypoints. These features capture spatial relationships between joints or movement patterns.
- Sequential Layers: Allows the model to exploit the temporal nature of the pose data, leading to more accurate pose estimation across a video sequence.
-
Transformer-based Model 🔄: Trained through extensive experimentation and hyperparameter tuning, this model offers enhanced performance and adaptability.
- Training Strategies:
- Warmup: Gradually increases the learning rate from a very low value to the main training rate, helping the model converge on a good starting point in the parameter space before fine-tuning with higher learning rates.
- AdamW: An advanced optimizer algorithm that addresses some shortcomings of the traditional Adam optimizer and often leads to faster convergence and improved performance.
- ReduceLRonPlateau: Monitors a specific metric during training and reduces the learning rate if the metric stops improving for a certain number of epochs, preventing overfitting and allowing the model to refine its parameters.
- Finetuned VideoMAE: Utilizes the pre-trained weights from VideoMAE as a strong starting point and allows the model to specialize in recognizing human poses within videos.
We have also implemented the VideoMAE model, proposed in the paper “VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training.” Fine-tuning techniques such as qLORA, peft, head and backbone fine-tuning, and only head fine-tuning were explored, with the latter proving to be the most successful approach.
Shruti-Drishti tackles the communication gap through a two-fold approach:
-
Sign Language to Text: Implementing a custom Transformer-based Multi-Headed Attention Encoder using Google’s Tensorflow Mediapipe, we convert sign language videos into text while addressing challenges related to dynamic sign similarity.
-
Text to Sign Language: Utilizing an Agentic LLM framework, Shruti-Drishti converts textual information into masked keypoints based sign language videos, tailored specifically for Indian Sign Language.
-
Pose-to-Text Implementation: Develop and implement a Pose-to-Text model based on the referenced paper for the Indian Sign Language dataset, using Agentic langchain based state flow as the decoder stage for text-to-gloss conversion and merging masked keypoint videos.
-
Custom Transformer Model Evaluation: Assess the effectiveness of our custom Transformer/LSTM model on the Sign Language Dataset, focusing on accuracy and adaptability to dynamic signs.
-
Multilingual App Development: Create a user-friendly multilingual app serving as an interface for our Sign Language Translation services, ensuring easy interaction and adoption by both deaf and non-deaf users.
-
Workplace and Educational Inclusion:
- Deploy the Sign Language Generation system in offices and educational institutions to facilitate seamless communication with the deaf and mute community.
- Empower individuals with hearing impairments by providing them with equal opportunities for education and employment.
-
Content Accessibility:
- Enable news channels and content creators to expand their user base by making their content accessible and inclusive.
- Offer services to embed sign language video layouts for content, fostering a more inclusive society and promoting equal participation.
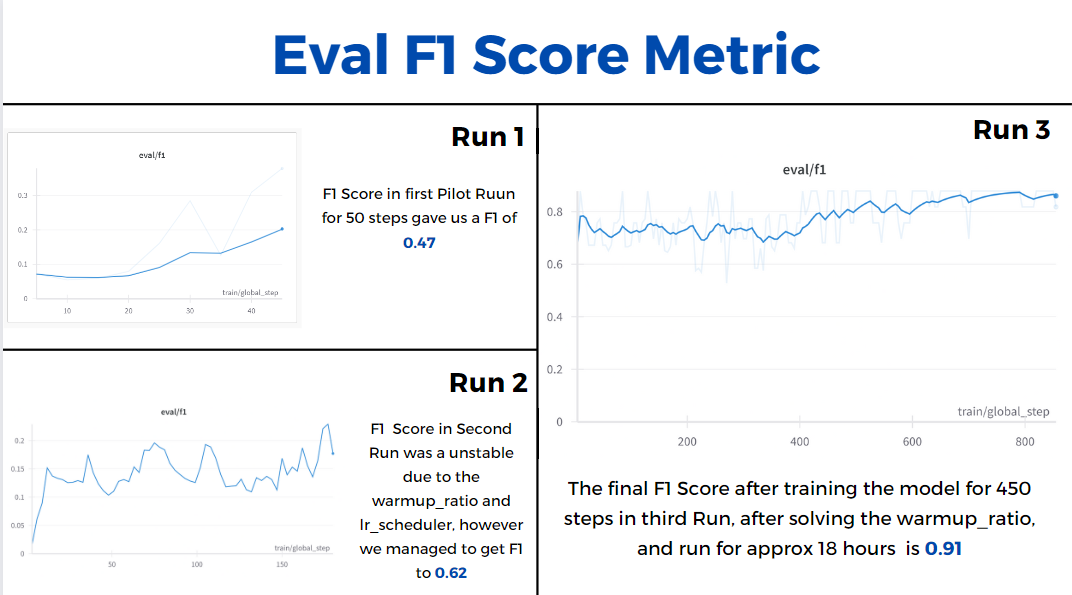
For detailed results and insights, please refer to our presentation slides.
(TODO)






{{ gettext('Login to leave a comment') }}
{{ gettext('Post a comment…') }}{{ errorMsg }}
{{ gettext('No comments posted yet') }}