The Human Colossus Foundation recently announced the release of its Dynamic Data Economy (DDE) v1.0 architecture, which includes the Principles and a Trust Infrastructure Stack as well as a rollout plan for a related suite of components:
- Overlays Capture Architecture
- Trusted Digital Assistant
- Data Governance Administration
The DDE is a framework to build a next-generation data-agile economy. It comprises of processes and toolkits that will help empower people and businesses to make better-informed decisions based on insights from harmonised, accurate data framed by sound data governance. DDE consists of a decentralized trust infrastructure for safe and secure data exchange, acutely aligned with the European data strategy where actors have the transactional sovereignty to share accurate information bilaterally.
In order to achieve a DDE architecture, one needs to underpin distributed data ecosystems with governance, semantics, and authentication, using a Master Mouse Model (MMM) (Fig. 1).
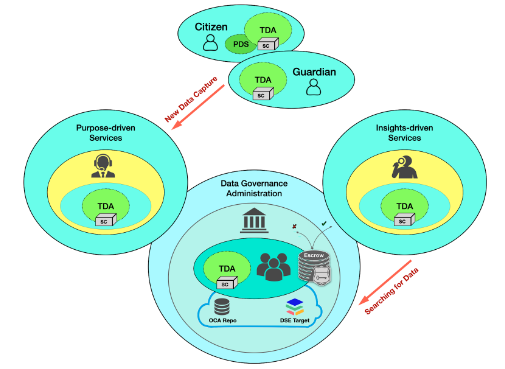
Fig. 1. Master Mouse Model
A MMM can be used internally within an organization or externally within a distributed data ecosystem. It has following features:
- Everything is citizen centric and it also consists of a Guardianship. For instance, if a citizen has dementia, then some of the legal authority might be pushed over to a guardian.
- A service model consisting of purpose driven services and insights driven services.
- Purpose driven services- when new data is captured into these distributed data ecosystems, for example a taxi service or a clinical service.
- Insights driven services- organizations or individuals that are searching for existing data within the ecosystem.
- Glueing all of that together is the idea of a data governance administration where they set the policy and rules and regulations for safe and secure data sharing within their ecosystem.
There are four core Synergistic Data Domains (Fig. 2) that are given an equal weight of importance under the DDE conceptual infrastructure:
- Semantic domain - data capture - “objectual integrity”
- Inputs domain - data entry - “factual authenticity”
- Governance domain - data access - “consensual veracity”
- Economic domain - data exchange - “transactional sovereignty”
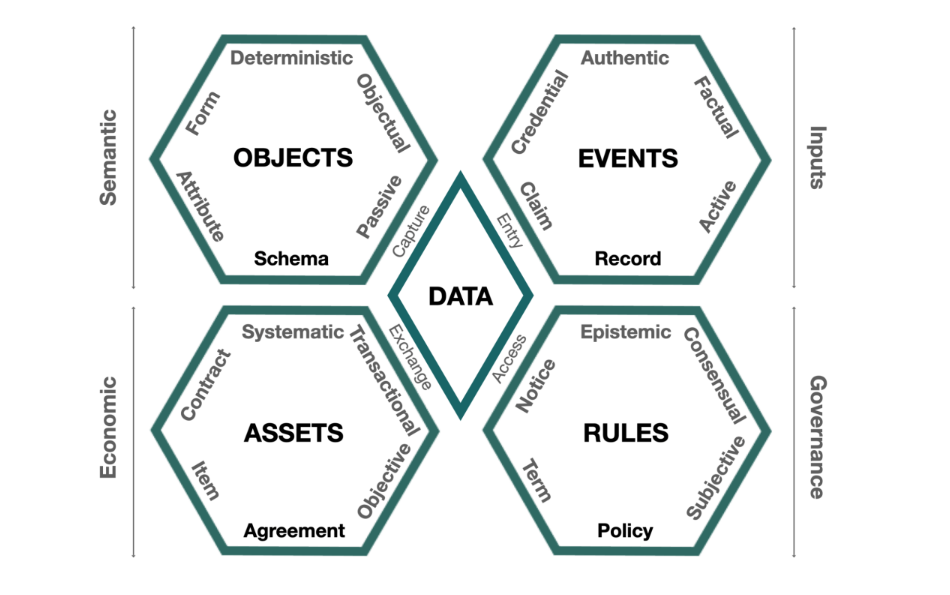
Fig. 2. Model of Synergistic Data Domains
The DDE Trust Infrastructure Stack (Fig. 3) is built out of these four data domains. It starts with semantics and objectual integrity, which is about data harmonization within the ecosystem. The next layer looks at factual authenticity, which is about where data is coming from and to a verifiable or auditable chain of provenance as the input domain. These first two layers are all about the machines and cryptographic assurance.
Once this digital network is in place, the human domains are put on top of that. The governance domain is at layer three, which is the policy, rules, and regulations layer within a distributed data ecosystem. The final layer is the economic domain, which is about transactional sovereignty between bilateral exchange in a peer to peer fashion. Hence, in this stack, trust infrastructure is equal to cryptographic assurance plus human accountability.
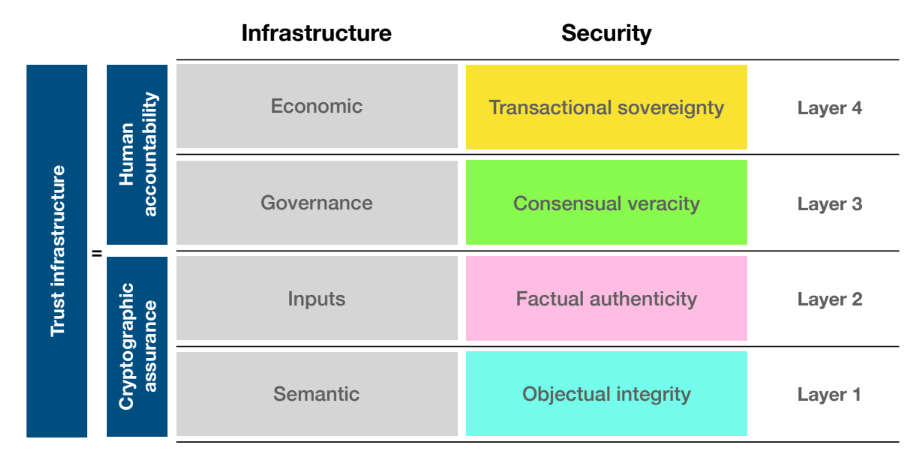
Fig. 3. DDE Trust Infrastructure Stack
As of now, the DDE focuses on the first three data domains - Semantic, Inputs, and Governance (Fig. 4).
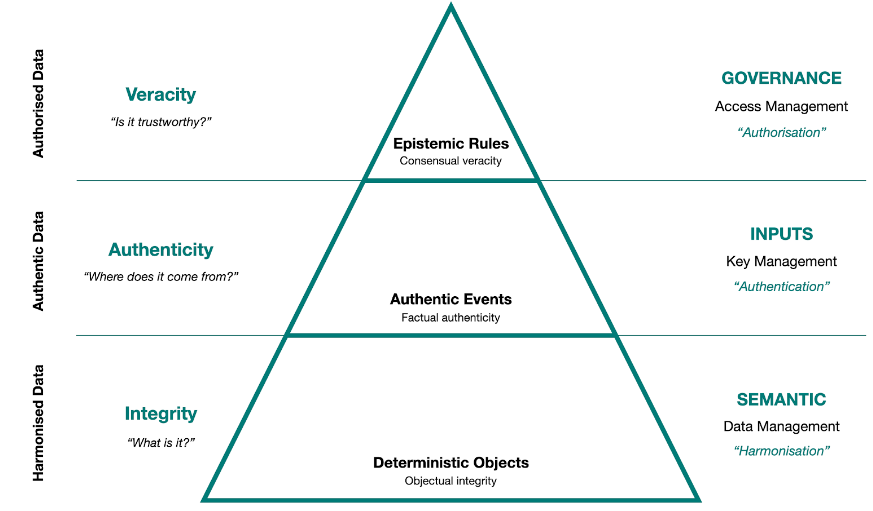
Fig. 4. The Accurate Data Pyramid
Data semantics is the study of the meaning and use of data in any digital environment. In data semantics, the focus is on how a data object represents a concept or object in the real world.
Within the semantic domain, the core foundational characteristic is objectual integrity - the overall accuracy, completeness, and consistency of objects and their relationships.
The Digital Network Model (Fig. 5) is about objects and events. The objects sit in the semantic domain, and the events are about the factual authenticity of what’s put into the system and sit in the inputs domain. The way to think about this model is to start with a schema and a record. They’re really the persistent objects in those two spaces. A schema is where one adds the structural integrity of the objects and then on the other side, how that information is stored is a record.
The form and the credential are separated in this model. A credential is a transient object that will allow one to do something, but how one captures the information that goes into a credential is usually from a form.
Everything in the semantic domain has to be deterministic. In a distributed system, immutable data is not particularly useful, because one might have a scalability issue with it. So one talks about deterministic objects in this case and that means that if one has the authorization to delete an instance of an object, then one can do that.
In the middle of the model, the active state talks about controlling information that one has entered into the system. Once one signs it, it becomes a fact. The other side of the model, i.e. the semantic domain is more about language rather than control.
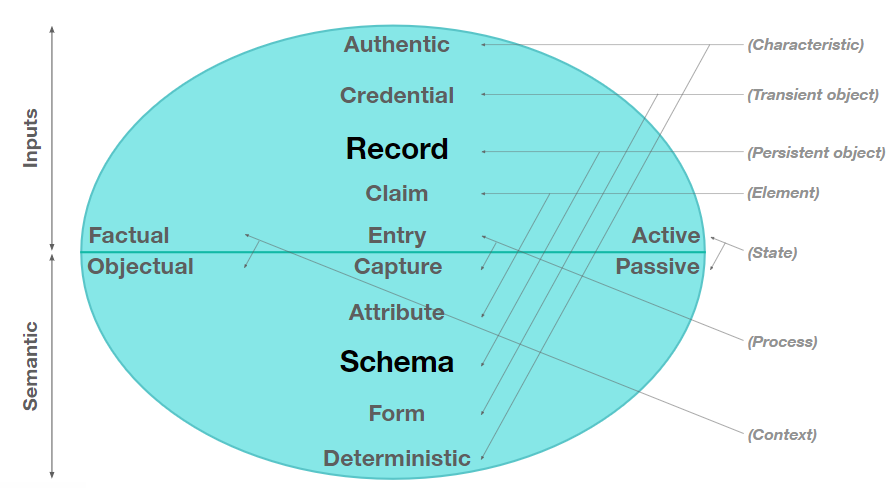
Fig. 5. The Human Colossus Digital Network Model
It involves separating all semantic tasks into separate objects so that different entities can act as custodians to those granular objects. This maximizes interoperability within the semantic structures within a distributed data ecosystem.
In the Semantic Domain, the core principles are as follows:
- Rich contextual metadata: The captured context and meaning (the “metadata”) for all payloads MUST be rich enough to ensure complete comprehension by all interacting actors, regardless of written language.
- Structured data forms: Data governance administrations MUST publish structured data capture forms, specifications, and standards, driven by member consensus for a common purpose or goal that will ultimately benefit the global citizens and legal entities they serve.
- Harmonised data payloads: There are two areas of distinction to consider. Data harmonisation involves transforming datasets to fit together in a common structure. Semantic harmonisation ensures that the meaning and context of data remain uniformly understood by all interacting actors, regardless of how it was collected initially. Harmonised payloads are a MUST for multi-source observational data to ensure that the data is in a usable format for machine learning and Artificial Intelligence.
- Deterministic object identifiers: If the result and final state of any operation depend solely on the initial state and the operation’s arguments, the object is deterministic. All object identifiers MUST be resolvable via the object’s digest to be deemed deterministic.
Decentralized semantics leads to data harmonization, i.e. different data models or representation formats being able to understand each other. Some use cases provided later/below will help illustrate this concept.
Fig. 6 illustrates data harmonization in a distributed data ecosystem. The transformation overlays are held by and can be controlled by the purpose driven services, and then cryptographically linked to a capture base to harmonize the information. The capture base is essentially a schema in its most basic form. The only thing it has is a flagging block software, using which the issuer can flag any sensitive information within the capture base. There are four transformation overlays for unit mappings, attribute mappings, entry code mapping, and standards mapping.
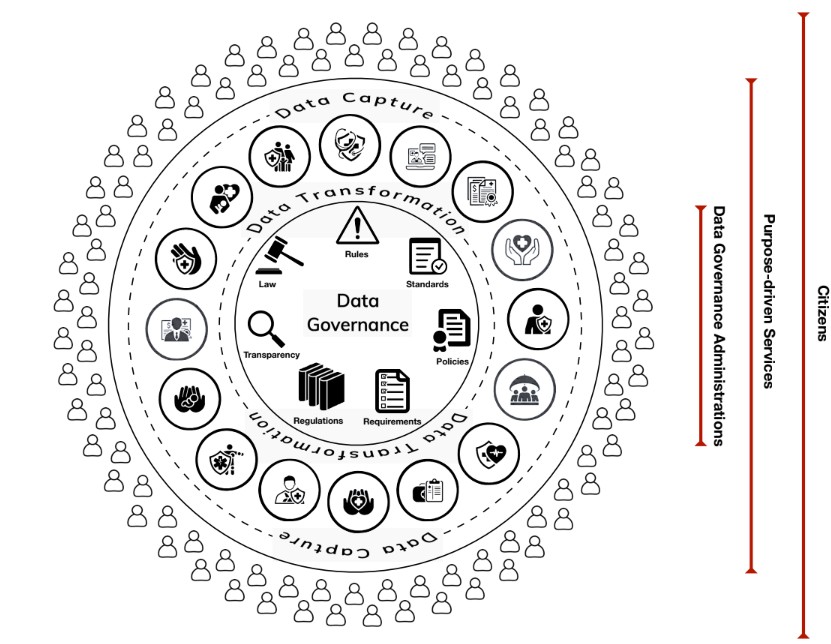
Fig. 6. Distributed data ecosystem
- Internationalisation
Internationalization is the action or process of making something international. So, the internationalization of transient digital objects across distributed data ecosystems is essential for service providers to participate in a global market.
Traditionally, presenting information for a purpose driven activity in a language understandable to all recipients has involved replicating digital forms, credentials, and contracts receipts into various languages based on user preferences with federated or centralized governance authorities maintaining digital objects in multiple languages. Internal data management inefficiencies are common to many organizations, institutions, and governments.
- Presentation
Presentation is about the ability to cryptographically bind presentation overlays to the standard capture base used for authentic data entry. So, in many presentation instances, the legal entity that issues the original capture form may differ from the entity that issues the presentation objects required to produce an associated credential.
This is about a multi stakeholder collaboration in building semantic objects, where any of the layers can be controlled by different legal entities, departments, or individuals who can have authorization for the custodianship of those objects. This shows one where the power of semantic interoperability lies.
The Overlays Capture Architecture is a global solution for data and semantic harmonization. It is a technical implementation of the decentralized semantics and is illustrated in Fig. 7.
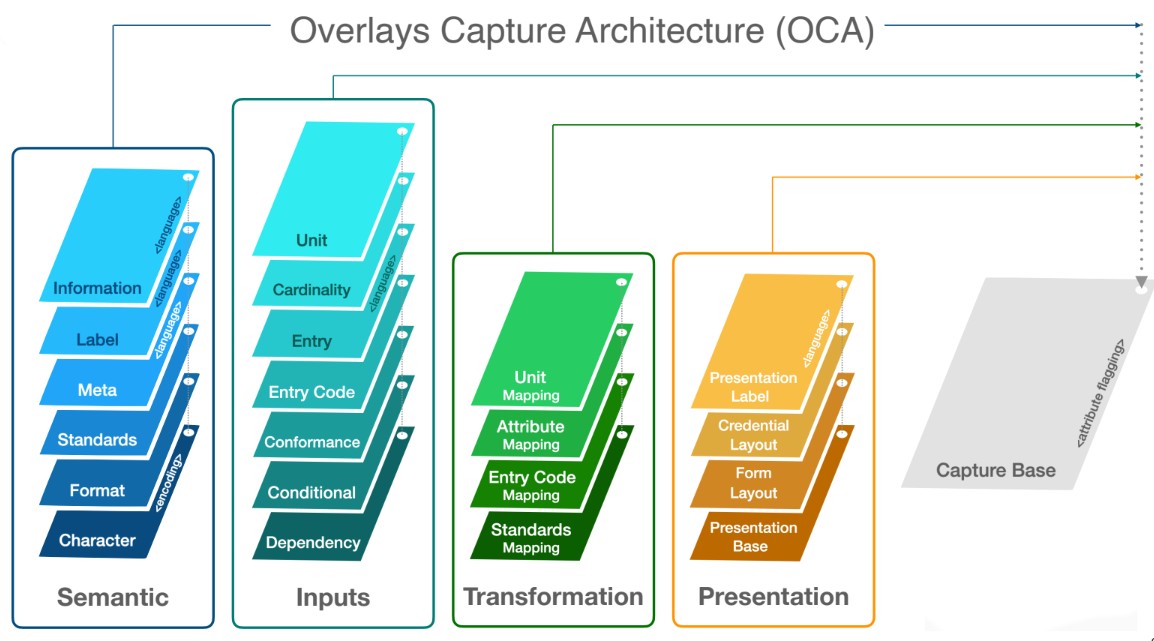
Fig. 7. Overlays Capture Architecture
Features of OCA:
- Semantics: This is about the context of the data, i.e. the meaning for the data that one is capturing. Some of these are language specific overlays. What this enables one to do is if one wanted to change the labels from say English into French, they could just build a label overlay in French and slot that into the stack, rather than rebuild the entire semantic structure. At the resolution side, they have the option of going into that new language.
- Inputs box: This is all about data inputs. So, this is where one can put a bit of control around what people are entering. If there are too many freeform text fields floating around then it becomes a potential point of attack. But also, more importantly, it’s then not particularly useful for data insights.
- Transformation overlays: This is about making sure one can go from the current way that they are capturing data as a service provider and mapping to the consensually agreed data capture specification from the data governance administration.
- Presentation box: This allows one to present different objects cryptographically linked to the same capture base but with different legal entities controlling them.
Benefits of OCA:
- Overlays Capture Architecture (OCA) offers a solution to harmonisation between data models and data representation formats.
- The key benefit of OCA is that different actors from different institutions, departments, etc., can control specific task-oriented objects within the same OCA bundle. In other words, different actors may have dynamic control over assigned overlays rather than the entire semantic structure.
- Object interoperability is essential in a data-agile economy where multiple actors from various institutions participate in complex use cases, supply chains, and data flows, supported by multi-stakeholder data governance administrations and frameworks.
Core OCA characteristics:
- Task-oriented objects
- Content-bound objects
- Deterministic identifiers
- Simplified data pooling
- Stable capture bases
- Flagged attributes
- Internationalisation
- Object presentation
- Composability
- Ontology-agnostic
- Multiple issuers
- Cross-platform
What is a Capture Base?
A Capture Base is a stable base object that defines a single dataset in its purest form, providing a standard base to harmonise data. The object defines attribute names and types.
The construct also includes a flagging block, allowing the issuer of a form or schema to flag any attributes where personally identifying information may be captured.
With flagged attributes, all corresponding data can be treated as high-risk throughout the data lifecycle and encrypted or removed at any stage, reducing the risk of re-identification attacks against blinded datasets.

Fig. 8. Code: Capture Base
What is an Overlay?
Overlays are cryptographically-linked objects that provide layers of task-oriented contextual information to a Capture Base.
Any actor interacting with a published Capture Base can use Overlays to transform how information is displayed to a viewer or guide an agent in applying a custom process to captured data.
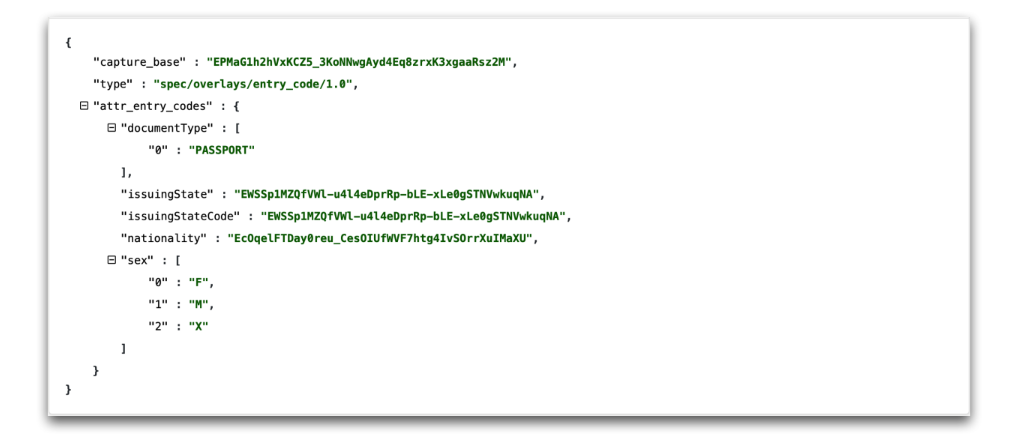
Fig. 9. Code: Entry Code Overlay
What is an OCA Code Table?
A code table (also known as a “lookup table”) is an array that replaces runtime computation with a simpler array indexing operation. The savings in processing time can be significant because retrieving a value from memory is often faster than carrying out an expensive computation or input/output operation. An OCA table is a lookup table that OCA can ingest.
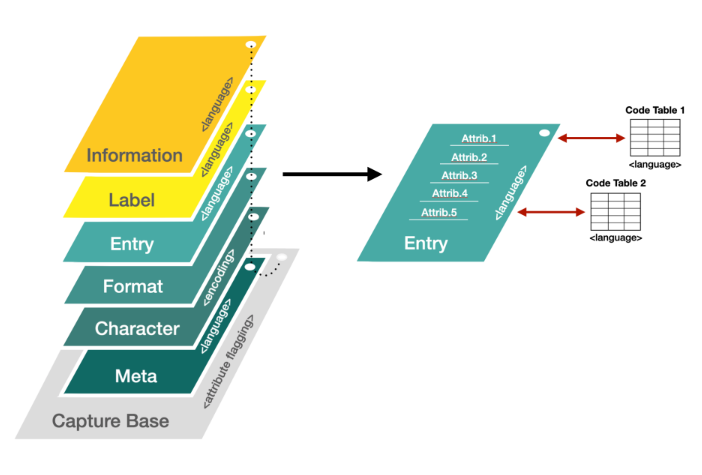
Fig. 10. OCA Code Table
Form Capture and Entry
There are four types of overlays that are involved in form capture and entry:
- Meta Overlay: A Meta Overlay is a core linked object that defines contextual meta-information about the schema, including schema name, description, and broad classification schemes.
- Entry Overlay: An Entry Overlay is a core linked object that defines predefined field values in a specified language. It is good practice to avoid implementing free-form text fields to minimise the risk of capturing unforeseen personally identifiable information (PII), quasi-identifiable information (QII), or sensitive information. This overlay type enables structured data to be entered, thereby negating the risk of capturing and subsequently storing dangerous data.
- Label Overlay: A Label Overlay is a core linked object that defines attribute and category labels for a specific locale. This overlay type enables all labels to be displayed in a preferred language at the presentation layer for better comprehensibility to the end-user.
- Information Overlay: An Information Overlay defines instructional, informational or legal prose to assist the data entry process.
What is the main significance of transforming different data models and representation formats into OCA?
OCA provides a fundamental step in building digital objects that, when resolved at the application layer, maintain the semantically-rich definitions to ensure that the meaning and context of data are uniformly understood by all interacting actors, regardless of how it was initially collected.
In doing so, all (i.) transient objects (e.g., forms, credentials, contracts and receipts), (ii.) documents, and (iii.) records held in transient containers (with credentials providing a transitive trust component for authorised access) will always contain harmonised data which, when pooled, provide a cleaner fuel for better AI, statistical analysis, machine learning and other insights-based solutions for a specified purpose.
In terms of data harmonisation, earmarked inputs from multiple sources can serve a common purpose. First, however, the source inputs need to be transformed into OCA structures to unify the semantics. Only through this capture process can the benefits of structural and contextual harmonisation occur.
The input domain deals with records which can describe identity. Identity is just a set of data points that describes who one is in a digital space. This section discusses how one can get to the position where they can trust those records and use them to operate in a digital space.
The foundational characteristic of the input domain is factual authenticity. Data can be assumed to be authentic if it is provable that it has remained incorrupt since its creation and lead to the source.
Decentralised authentication describes a key management methodology of cryptographically binding self-certifying identifiers (SCIs) to an associated log that compiles the history of all uses or changes to the public/private key pair, ensuring verifiable identifier provenance throughout any ambient infrastructure.
Immutable ordering guarantees the factual authenticity of the recorded event underpinning any systematic data input.
Furthermore, all system identifiers must remain network-agnostic, enabling identifier interoperability within and across any distributed data ecosystem.
Key management refers to the management of cryptographic keys in a cryptosystem, dealing with the generation, exchange, storage, use, crypto-shredding and replacement/rotation of keys. It includes cryptographic protocol design, key servers, user procedures, and other relevant protocols.
In the Inputs Domain, the core principles are as follows:
- Authentic data events: All recorded events MUST be associated with at least one public/private key pair to be considered authentic. Public/private key pairs provide the underpinning for all digital signatures, a mathematical scheme for certifying that event log entries are authentic.
- Verifiable event identifiers: Data provenance provides a historical record (an “event log”) of the data and its origins. All event identifiers MUST be cryptographically verifiable to ensure data provenance, which is necessary for addressing validation and debugging challenges.
Decentralized authentication helps in data authentication. If one has a method for auditing the flows of data that allows them to secure the data in a way that doesn’t depend on one specific location, then they are able to enrich the ecosystem with data flows. So, with this approach, one secures the data, and not the location, which enables a flow of the data across multiple parties, multiple jurisdictions, and multiple entities in a secure and privacy-preserved manner since one can verify who owns, handles, and controls that data.
One can also audit any interaction in any part of the ecosystem, independently from any network or system provider to check whether the information which one possesses is something that was obtained legally. This is how decentralized authentication is useful in authenticating data.
- Autonomic Identifier: Key Event Receipt Infrastructure (KERI)
The most important aspect is to create some kind of an identifier and then one can represent themselves in a digital space that they can use for any interactions with anybody. This applies to any use case where one needs to identify something such as businesses, devices, IoT supply chains, etc.
This boils down to a lack of understanding of the differences between authentication, authorization, and identification. What a system should know is all three of those aspects at the same time with respect to the person trying to access the data.
- Microledger:
- End verifiability
- Composability
- Ownership Transferability
- Plugable
- Authentic Chain Data Containers (ACDC) -> Verifiable credential
In a data provenance chain, the cryptographic link objects allow one to build up a zero trust platform, wherein users are always verified. One can also check whether the chain was broken or not. As a result of cryptographical properties, one can be assured that the chain was not broken. This can then be used for a different verifiable credential mechanism, the authorization mechanism, traceability, and transparency.
-
Authorization
-
Legitimized Human Meaningful Identifiers
Legitimized human meaningful identifiers are identifiers which do not have security properties like email addresses, which anybody can own depending on who owns the domain. With a decentralized authentication technology, this can be done in a way where one can truly own that human meaningful identifier.
In order to interact with a device in a digital space, one needs a system. For this purpose, say one has a hardware which operates with a software and the two are securely bound in a way that nobody can tamper, modify, or run malicious pieces on. Nowadays, such hardware is equipped with technologies like trusted platform modules, secure elements, etc. which are sub systems designed in a way that as soon as one puts the key in it, there is no physical possibility to extract or steal that key.
Say, if one has a mobile device, when they unlock their phone with their fingerprint, there is a secure binding between them as a human being and the hardware, which actually stores the keys for them. This is a biometric link towards security enclaves where it actually helps one store the key. This allows the system to link that security with the human being and then the software running on that hardware gives one the possibility to have the full stack connected.
While using that identifier within the digital space, one can actually use the private key security stored on their device to sign messages, verify information, or encrypt information if needed.
Now, the system needs to be managed in a way such that the user does not need to worry about losing their identity just because they lost their device. This is where the concept of the trusted digital assistant comes in. The TDA is not an app or a mobile device. It is basically a set of the components which could be run in the form of the agent and it could be run on any device as required. In many cases, one will need to have a governance around that which helps them to manage that TDA.
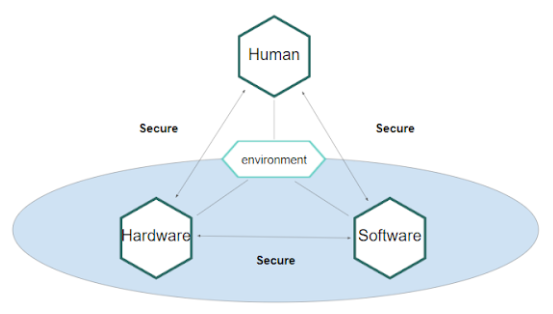
Fig. 11. Trusted Digital Assistant
Benefits of a TDA:
-
It allows one to create ecosystems where people don’t need to deal with the technical complexity of a system but they still trust the organization, which deals with the technicalities for them. It also allows one to choose who they trust with these technicalities and their identifiers, without having any impact on their digital interactions and how they operate in that digital space.
-
It gives one the possibility to create an ecosystem which is completely network agnostic. There is no platform, blockchain, network, federated or decentralized ecosystem behind it. It is truly decentralized from the perspective that one can take their choice and move to another sandbox whenever they don’t like the one they started with. This is very important because many systems in the space of identity and authentication systems assume certain boundaries of those identifiers and digital interactions.
Additionally, instead of trying to solve the problem on the protocol level, as it is suggested, by a Key Event Receipt Infrastructure (KERI), organizations try to solve that problem on the higher layers and then hit different sorts of limitations. Hence, it is very important to understand that the decentralization of a system increases the sovereignty of the user who can decide where to go and where they want to operate, even if the governance is compromised.
- One then has a mechanism to recover their keys and identifiers, and can also switch governance anytime and move elsewhere without much loss in their digital interactions.
Ideally, data governance is a system of decision rights and accountabilities for information-related processes, executed according to agreed-upon models, which describe who can take what actions with what information and when, under what circumstances, and using what methods.
In realistic terms, data governance is a set of policies, rules, and regulations within an enterprise, which enterprises are free to develop themselves since these are internal rules. These rules are within a jurisdiction that respect external laws, but it’s still the enterprise that decides its governance model in function of its scope. However, it also goes with all the procedures to enforce it.
Governance is a set of documents of rules, but there is also an enforcement aspect and a human aspect. It is important to note that data governance is always balanced with the business interest.
- Data Governance at micro-level:
-
Growing complexity > rising costs
The numbers of regulations and complexities from interaction give rise to a highly complex ecosystem. This translates to rising costs, not only monetary terms, but also in human terms since one needs more people to take care of the various aspects of data governance and compliance.
-
Eroding trust > slows innovation
Another problem is the eroding trust that people have in data governance because the protection is often not felt. Due to this, it is very hard to convince someone to share their data for research purposes as they fear that their data will be used elsewhere as well, without their consent. So, the erosion of trust slows down innovation.
- Data Governance at macro-level:
-
Growing complexity > multi-jurisdiction agreements
Since today’s world is more and more interconnected, most of the applications developed today require the connection with various stakeholders. This multi stakeholder environment translates into a multi jurisdictional environment. As a result, one needs to get everyone agreeing on a center of trust. However, usually the center of trust doesn’t want to take this responsibility globally. This slows down the process.
-
Eroding trust > loss of diversity, platform-locking
In any data governance, there is an existing trust element that allows the system to be built on this trust element and it must exist usually before one goes to the digital space. It is sometimes forgotten that it’s not the digital credential that will give one the trust, it’s actually a digital representative of an existing trust. The erosion of trust is more on the economical side because of the way trust is enabled in a digital system. There is a centralization of trust on a certain number of platforms. Some of these platforms, such as social media platforms, are usually concentrating power on users, and the network effect is starting to bring some kind of platform locking, which then creates a problem for all the businesses on it.
While designing governance, one should not follow the technology road, i.e. from centralized to distributed systems. Governance is more about how humans exchange information and it should go the other way around, i.e. start with individuals and build stronger and larger communities. Whether one wants to address the macro level or the micro level of the governance problem, it might be best to first start with the existing human trust framework that starts with the individual and then build an increasingly larger structure.
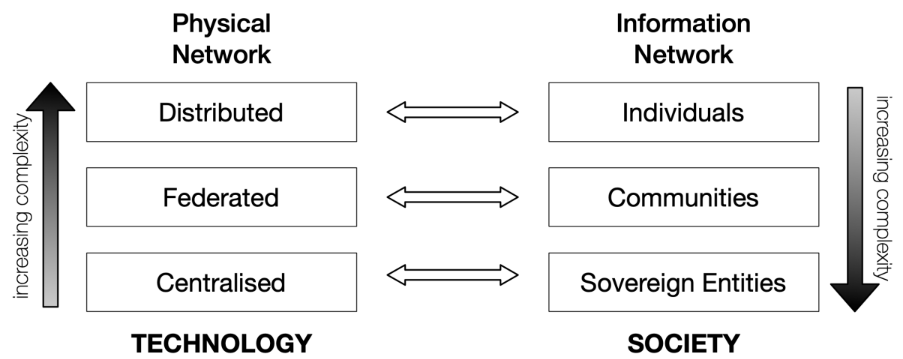
Fig. 12. The Technology vs. Society Complexity Dilemma
Distributed data governance provides a powerful solution for
- multi-stakeholder collaboration
- based on rules & regulations
for safe and secure data sharing within and across distributed data ecosystems.
It describes an operational framework for the provision of
- rules,
- common standards and practices,
- infrastructures,
creating a distributed trust framework to empower individuals through increased digital access to (and control of) their electronic personal data, nationally and cross-borders, fostering a genuine single market for electronic record systems, relevant components and high-risk artificial intelligence (AI) systems.
Multi-stakeholder participation within Data Governance Administrations guarantees the consensual veracity of purpose-driven data agreements while providing a consistent, trustworthy and efficient set-up for personal data use for research, innovation, policy-making and regulatory activities.
In the Governance Domain, the core principles are as follows:
- Reputable data actors: Data governance administrations MUST exercise vigilance to ensure that all ecosystem participants involved in digital interactions under their administrative control are reliable and trustworthy.
- Accountable data governance: Data governance administrations MUST assume responsibility for the veracity of epistemic rules for safe and secure data sharing on behalf of the global citizens and legal entities they serve.
- Searchable distributed databases: Data governance administrations MUST house at least one distributed database that insights-based service providers can utilise for structured criteria searches and data requests.
- Monitored data requests: Data governance administrations MUST ensure that domain experts constantly monitor dynamic search engine targets under their administrative control to protect members against unethical or sensitive incoming data requests.
- Consensual policy: Privacy rights, data governance policy, and licences MUST provide the legal basis for safe and secure data sharing within and between sectoral or jurisdictional ecosystems for a particular purpose.
What is Consensual Veracity?
The foundational characteristic of the Governance domain is “consensual veracity”, a term coined to capture the overall truthfulness and accuracy of shared data. In the case of any multi stakeholder distributed data the veracity of the information used for decision making relies on a consensus that has to be reached between the decision maker and the information system.
This consensus requires authentic information systems, trust being delivered by each ecosystem governances.
The aim is that there’s an interaction of multiple governance that is built on the same person. And here we to make it where it is this decentralized, this data governance administration have to respect a certain number of principle, to be able to determine which other reputable actors the accountability aspect, what data can be searched, and then monitoring of the data requests and important aspects to avoid surveillance in places where you don’t want to do that on all the consent measurements.
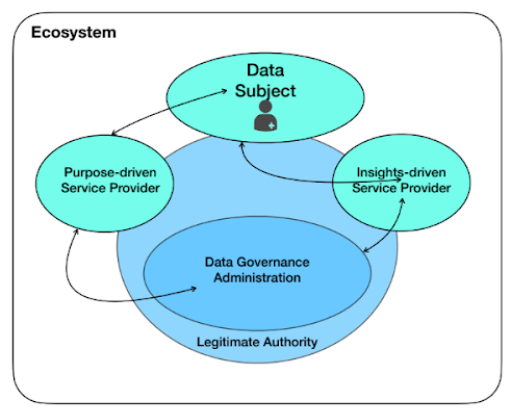
Fig. 13. The Distributed Governance Model
Autonomic agents, i.e. agents being capable of freewill deciding, are crucial for governance. There is no governance if one doesn’t have implementation and enforcement of the governance which leads to accountability. This is somehow related to the choice one is making when they do an action or not.
Autonomic agents can be individuals, but the term is also for organizations that, within its ecosystem, have the will to decide whether to do a business or to develop a relationship with a sovereign entity or not. There is some kind of freewill at the entity level that applies when one has this mechanism of choice. This is referred to as the data subject in Fig. 13.
The ecosystem is split up into purpose driven and insights driven service providers. This is an important distinction that clarifies the governance aspect, since one captures data and the other analyses it. Both these processes need to have proper data governance systems in place.
The blue circle in Fig. 13 represents the legitimate authority that governs the ecosystem. The authority will issue the regulations that the data governance administration can work on.
Everything in this model is based on peer to peer connection and the data subject can and will be a member of multiple ecosystems, usually simultaneously.
Privacy Mode is a growing community on data privacy, with a focus on engagement with policy and improving the overall privacy ecosystem from consumer and maker standpoints. Privacy Mode is hosted under Hasgeek.
One can find work done under Privacy Mode here.
Hasgeek is a platform for building communities. Hasgeek believes that effective and sustainable communities are built in a modular manner, and with an underlying layer of infrastructure and services that enable communities to focus on the core of their work. Hasgeek provides this infrastructure, and the capabilities for communities to amplify their work and presence.







{{ gettext('Login to leave a comment') }}
{{ gettext('Post a comment…') }}{{ errorMsg }}
{{ gettext('No comments posted yet') }}