Zeotap is a fully privacy compliant customer data platform that created a product to comply with GDPR regulations. They distilled the GDPR into a list of product requirements:
- Sensitive Data Management
- Consent management
- PII management
- User Information
- Access Management
- Auditing
- Miscellaneous requirements
- Hashing and Encryption from Security perspective
- One Time Requirements
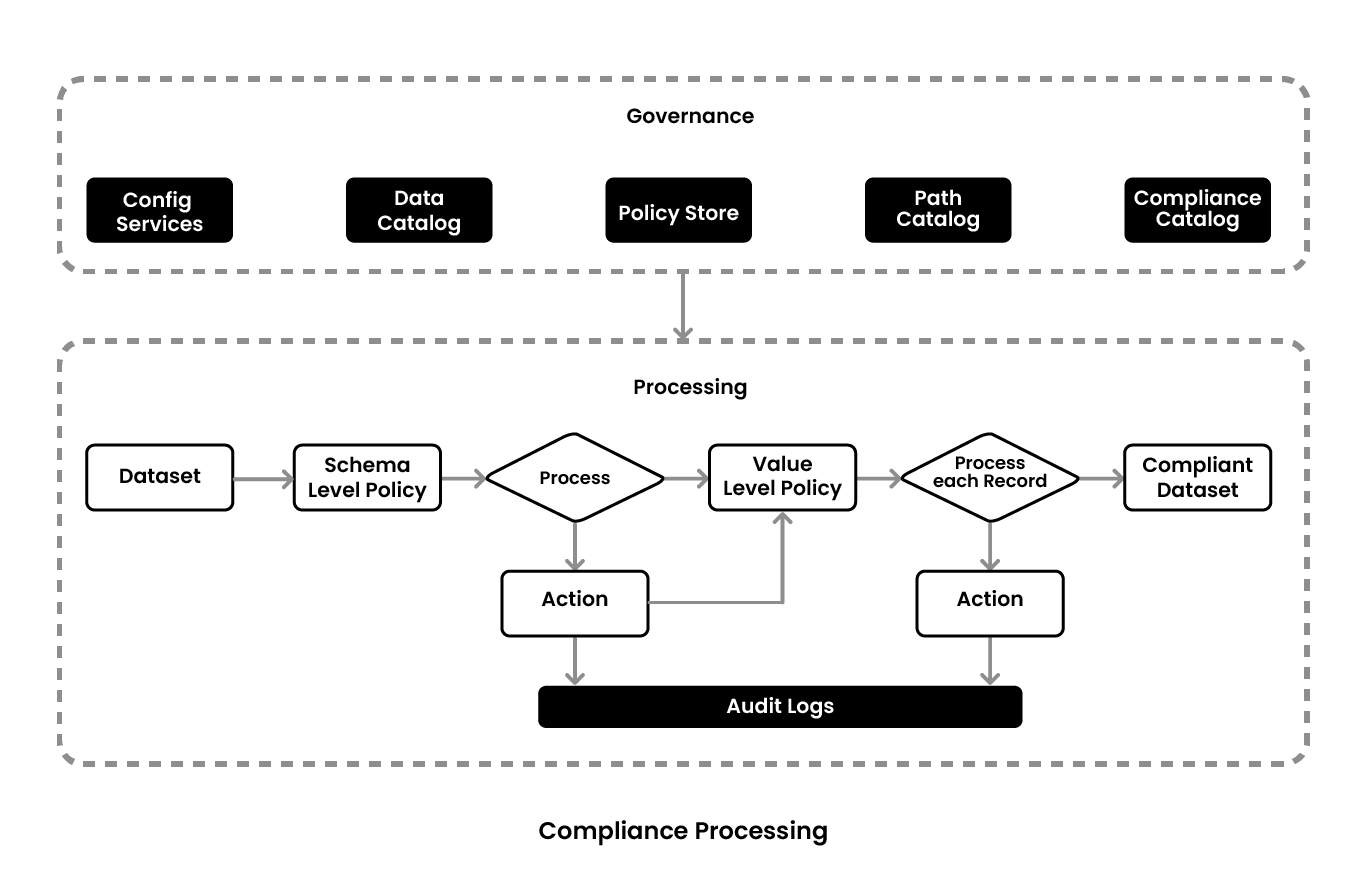
These requirements are conceptualized into three layers consisting of specific core components in each layer - logical, processing, and rules/policies. Compliance processing includes two aspects, how it is governed and how it is processed. Governance is achieved through five services, config services, data catalog, policy store, path catalog, and compliance catalog which feeds into data pipelines to orchestrate the compliance. In the processing pipelines the datasets go through first the schema level policy processing activating needed compliance actions and then value level policies which operate on each individual record and spews out the compliant data set. Relevant audit logs are written in both processes.
By virtue of Zeotap’s business consent inflow is from three different sources - Zeotap direct, from Data Partners and the third is the data consumers. For Zeotap direct, it is a Global opt-out where Zeotap has to remove the users’ data out of its systems and notify the downstream system as well to remove the data. When it comes to the Partner level, Zeotap only has to nuke the knowledge that the data partner has given them. Lastly, at the Consumer level, when the user opts out of one of the consumer channels, the channel informs Zeotap that that particular user is opting out. Then, Zeotap has to filter out the data of that user before processing and sending data to that channel.
To comply with the audit requirements, logging is mandatorily done. Logs are stored in buckets and loaded to OLAP databases where they can be analyzed. The logs were abstracted with a Compliance Logger library and a microservice so that they adhere to a common structure.
Terms/Glossary
- GDPR: General Data Protection Regulation
- OLAP: Online analytical processing
- PII: Personal Identifiable Information
- TTL: Time-to-live is a value for the time period that a packet or data should exist on a network before being discarded.
- CRUD: Create, Read, Update, Delete
- API: Application Programming Interface
- GCS: Google Cloud Storage
- SFTP: SSH File Transfer Protocol
- TCF: Transparency and Consent Framework
- MAID: Mobile Ad ID
Zeotap is a Customer Data Platform which enables brands to better understand their customers. They provide three items to achieve this - a 360 view of the customer data, identity resolution, and enable activation. They are a SaaS and DaaS offering who are people centric data collectors and the data collected can be categorized as Identity Data assets and Profile Data assets. Another style of categorization is deterministic, where the data they collect is based on deterministic identifiers. Based on their patented algorithms, they also do some inferences and derivations which they call probabilistic data. Zeotap is fully privacy and GDPR compliant and caters to 150+ ingress and egress data partners. The main stacks that they have integrated with are the AdTech and MarTech layers.
When GDPR was introduced, it had an effect across organizations and various teams within such as the business teams, product teams, legal teams, as well as security teams. The law talks about:
- Personal Data - data collected about any EU citizen which is identifiable to them
- User Rights - rights that an EU citizen has on their data that has been collected by an organization
- Access Rights - includes access rights of the user as well as within the organization
- Data Handling and Transport- recommends ways to handle and transport data
- Audit requirements
- Penalties - heavy penalties for anyone that fails to comply
GDPR has two categories of companies handling data - Data Processor and Data Controller - and Zeotap falls in both categories.
They distilled the GDPR into a list of product requirements:
- Sensitive Data Management - one of the prime requirements of GDPR was on handling sensitive data such as data on people’s ethnicity, health history, PII information, etc.
- Consent management - one has to be explicit about the consent that they’re collecting.
- PII management
- User Information – there are multiple user rights such as the right to be forgotten that need to be upheld
- Access Management
- Auditing - specific to companies
- Miscellaneous requirements - cohort minimum size and TTL in Zeotap’s case
- Hashing and Encryption from Security perspective
- One Time Requirements – Existing data cleanup
In the conceptual model of the product, the primary entities are the user and data assets. In terms of processing, one needs some kind of compliance processing which can permeate across all the layers of processing in the system across all products as well. Then, to meet the product requirements, everything that has to be done becomes policy or rule sets. For example, validating hash length for hashing encryption, validating sensitive data, etc. All of these become first class entities in the product.
If consent is opt-out, one needs deletion. This is not simple in large datasets, especially if one is storing in multiple data layers. Hence, the deletion processor workflow needs focused handling, and the same thing applies to TTL. These are the different entities that are required, as illustrated in the diagram below.
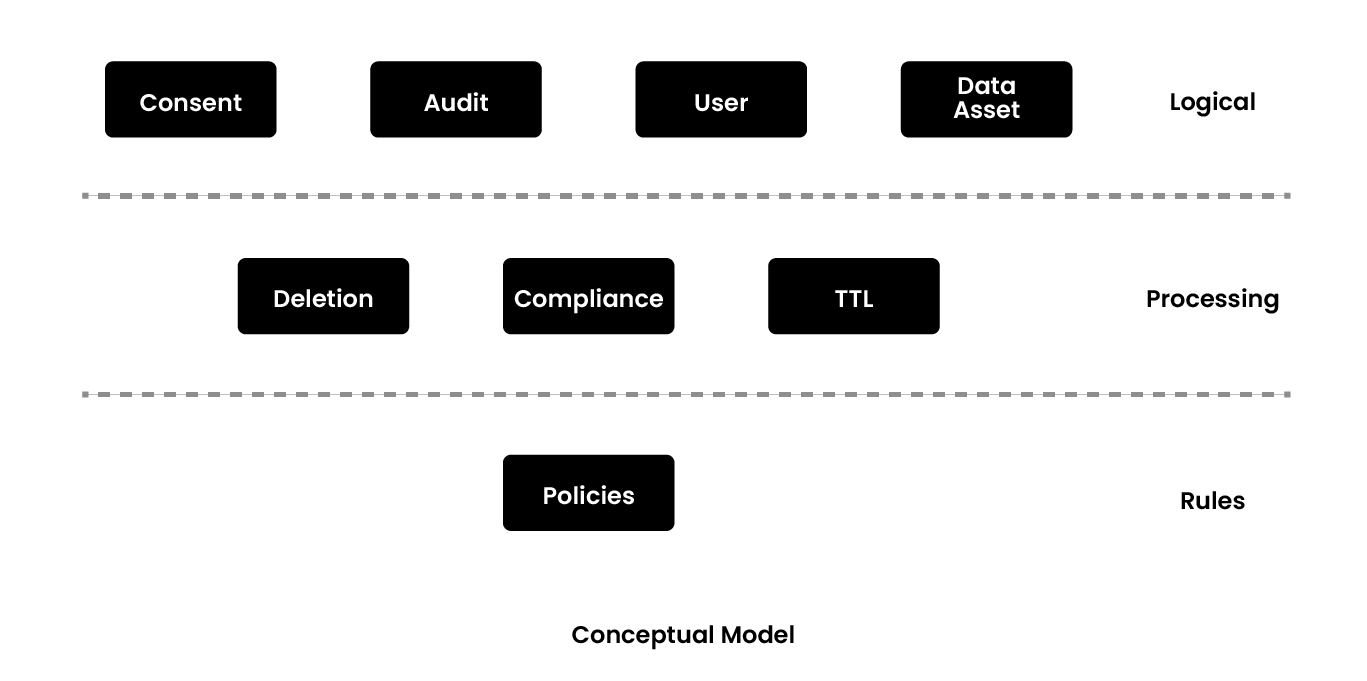
The first things that one needs to be privacy compliant are a clean data inventory, data catalog, and lineage system. This should include the following details:
- Who gives the data? – Partner, Region, Data Categories
- What does the data contain? – Schema, Field Types, Cardinality, Expected Values
- How does one describe it? - whether it is a raw data set or has been inferred or derived
- When did you get this? – when the data flows from system to system, the downstream system might be acting on a completely different version than what the upstream system is handling. So, the version and timestamp of the dataset is important.
- Where did a particular data point come from? - since data is collected from multiple third-party sources, one should know which data partner has contributed to the knowledge of an attribute at every attribute level.
- Resolution of conflict - if there is a conflict between data partners about the data that is being processed, compliance takes the highest priority, then quality takes the next priority, and so on and so forth.
This product was built over RDBMS and Elasticsearch stack and it has a microservice and library support. The library support is mainly for the spark processing aspects. When datasets get on-boarded and are processed, there are updates happening to the catalog such as knowledge aggregation. The product has now evolved to accommodate quality stats and verification, and is migrating to specialist toolsets like Apache Atlas. This is the primary technology that was used in the architecture.
The second entity is policy management. Policies are a combination of two things, rules and actions. The product has a set of actions as well as it is extensible to create custom actions as well. Some of the actions include drop action, alert action, null action, etc. The policies also have hierarchical support. Policies and actions are defined by domain experts instead of engineers, so they need to give CRUD (create, read, update and delete) via API’s to power users, which could be the legal team, account management team, product team, etc.
The compliance catalog has two use cases, which are separating the actual runtime parameters for the rules and the thresholds for the rules from the actual rule itself. In database parlance, this is called a normalization which helps in more flexibility and evolutionary control as well. What happens is the function of policy plus the function of the parameters which the compliance catalog provides gives you the action, i.e. F(Policy) + G(Param) = Action to be actuated. This is broader than the complex catalog. It has a blacklist, whitelist, and translations, so that the backend and UI can consume it as well.
Apart from the data catalog, policy store, and compliance catalog, there are two more aspects to data governance which are the config service and path catalog. Config service includes the actual Spark job properties and Spark comprehensive, because for each of the workflow, there is the item which is being processed and it needs a separate set of properties. These are all maintained by the config service.
Path catalog is for trigger based mechanisms. Data partners put data into various GCS paths and the path catalog tracks them and helps in triggering the workflow at the right times. Once that workflow is triggered, it also knows that the next workflow has been triggered and registered as a path which is available. It is kind of a metadata on the pipeline itself.
The data partner comes in and uses the governance mechanism to figure out the schema level policy. Then, it does the processing, takes actions, and writes the relevant audit logs. After this, it goes into a loop where it looks into the value level policies. These policies have to be applied on the record level or the row level. So, for each record, if one looks at the value level policies and takes the actions, they get a compliant data set. This is how the data catalog, policies, and compliance catalog work together in the actual workflow.
Opting out means that the user wants out of the system. There are nuanced opt outs as well as nuanced consent. Depending on the purpose with which the user opts out, it could be a blanket opt out or a purpose level opt out. The same applies for giving consent as well, either blanket consent is given or purpose driven consent is given.
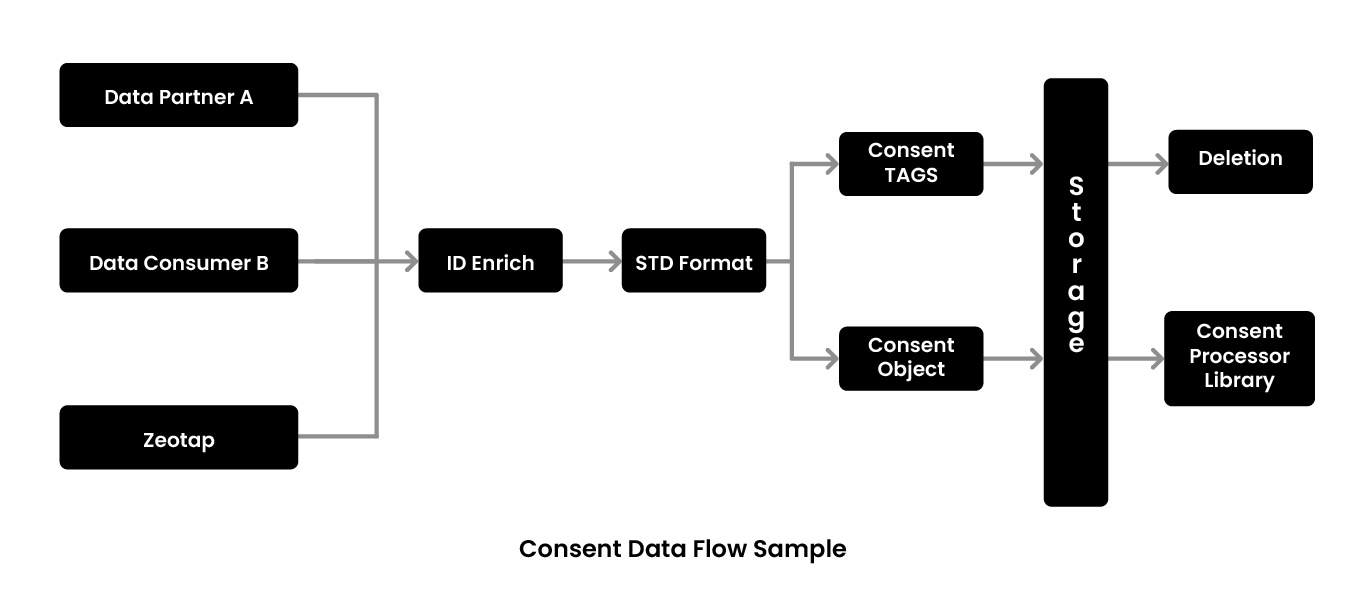
Zeotap has three modes of collecting consent. Given that they are a data controller as well, they are obliged to create a privacy website as well as an app. This is the Zeotap consent that flows into the API into the back end system and comes into the pipelines. The second mode is the data partners and the third mode is the data consumers. There are multiple mechanisms here since some data partners use cloud transfers while others use SFTP.
Based on how consent comes into the system, there are three modes of handling it. For Zeotap consent, it is the Global mode because the user is directly telling them that they want to opt out of the system. Zeotap then has to remove the users’ data out of the system and notify the downstream system as well to remove the data. When it comes to the Partner level, Zeotap only has to nuke the knowledge that the data partner has given them. Lastly, consumers are channel partners such as Google, Facebook, Instagram, etc. At the Consumer level, when the user opts out of one of these channels, the channel informs Zeotap that that particular user is opting out. Then, Zeotap has to filter out the data of that user before processing and sending data to that channel.
The latest development in this product is that it is now TCF (Transparency and Consent Framework) compliant. This helps in managing consent at a blanket level across the cookies and mobile identifiers.
Consent flows from one of the three modes mentioned above to ID enriches. Consent can come via an email ID and the first thing Zeotap does is figuring out all the IDs linked to that email ID and converting it to hash. Then, based on the hash and all identifiers which are linked to the hash, these are converted to the standard format. The same applies for data partners. After linking all the IDs together, the consent object is created. Consent tags are the purpose with which one opts out. If consent is not given, no further processing is done on that data and it moves to deletion. Otherwise, the data is processed further depending on the Consent Processor Lib as a Boolean for any of the downstream processing.
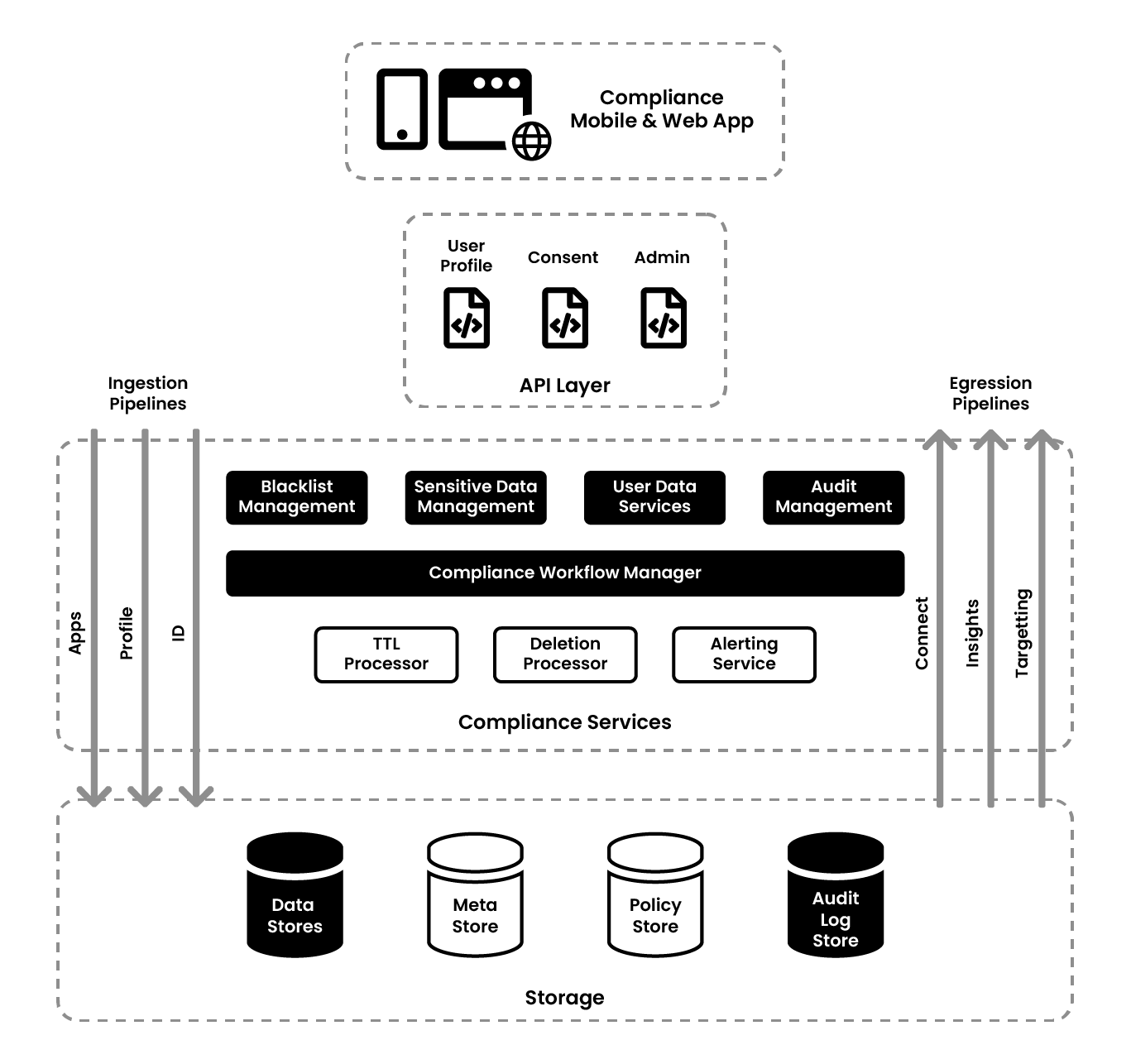
The next thing to look at is user management. The primary keys are MAIDs, Cookies, Hash Email, and Hash Phone Numbers, which are the identifiers for Zeotap. They created a mobile app and website which interacts with the backend API based out of Java Play Framework. Given the size of the data set, Zeotap used Bloom Filters, so that the identifiers could check whether it is present or not. All the identifiers are stored in a DB called Aerospike.
To comply with the audit requirements, logging itself was audited. Logs were stored in buckets and loaded to OLAP databases where they were analyzed. The important thing is to make sure that the logs are structured, so the logs were abstracted with a Compliance Logger library and a microservice. The logs grammar include:
- ViolationType
- Product Code
- Dataflow stage
- Action taken
- Action Timestamp
- Violation Timestamp
This service is used across layers like Spark, the backend layers, etc. and the log is aggregated into a single place and stored in buckets. This can then be loaded and analyzed.
The pipeline summary for this product is as follows:
- Deployed on ~80 workflows
- Now ~400 flows - Scaling
- Survived Cloud migration as well - Resilient
- Accommodated CCPA with minimal efforts - Extensible
All the infrastructure is split region wide and data sovereignty is taken very seriously. For example, data from the EU stays in the EU even for processing, and the same is true for data from different regions. Zeotap has a couple of certifications for access rights control which is based on minimum privileged access across all the datasets. They have a Chief Data Officer as well as a security person who does quarterly audits on this and passes on recommendations to the infra team. The ID and profile is always pseudonymized except during runtime processing. Additionally, the email and phone numbers are hashed. One can easily validate the hash against regexes.
Recommended certifications are:
- ISO 27001
- BSI CSA Star
- ePrivacy Seal
Tech stack/Tech solutions:
Apache Atlas
Apache Spark
ScyllaDB
Java Play Framework
RDBMS
Elasticsearch




{{ gettext('Login to leave a comment') }}
{{ gettext('Post a comment…') }}{{ errorMsg }}
{{ gettext('No comments posted yet') }}